- hw1: https://rail.eecs.berkeley.edu/deeprlcourse-fa23/deeprlcourse-fa23/static/homeworks/hw1.pdf
- https://github.com/julyfun/homework_fall2023
回忆提纲
本作业是 2023 版本的 imitation learning 和 DAgger. 而 2026 版本已经改成了 MLP-based Flow matching + PushT,而且总算没有证明题了.
回答问题
1.1 Given
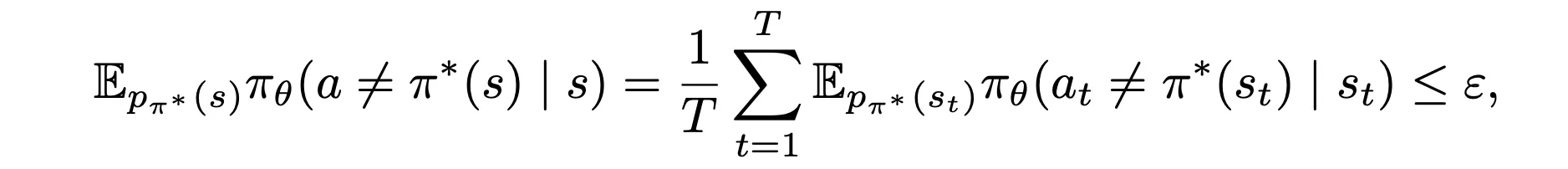 show:
show: 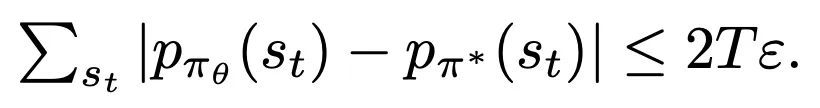
- see: https://blog.csdn.net/weixin_55471672/article/details/138329230
- 第一题我证半天不会证,给我整笑了.
1.2

- holy!
- The Off-policy policy gradient: 这张图简单易懂:

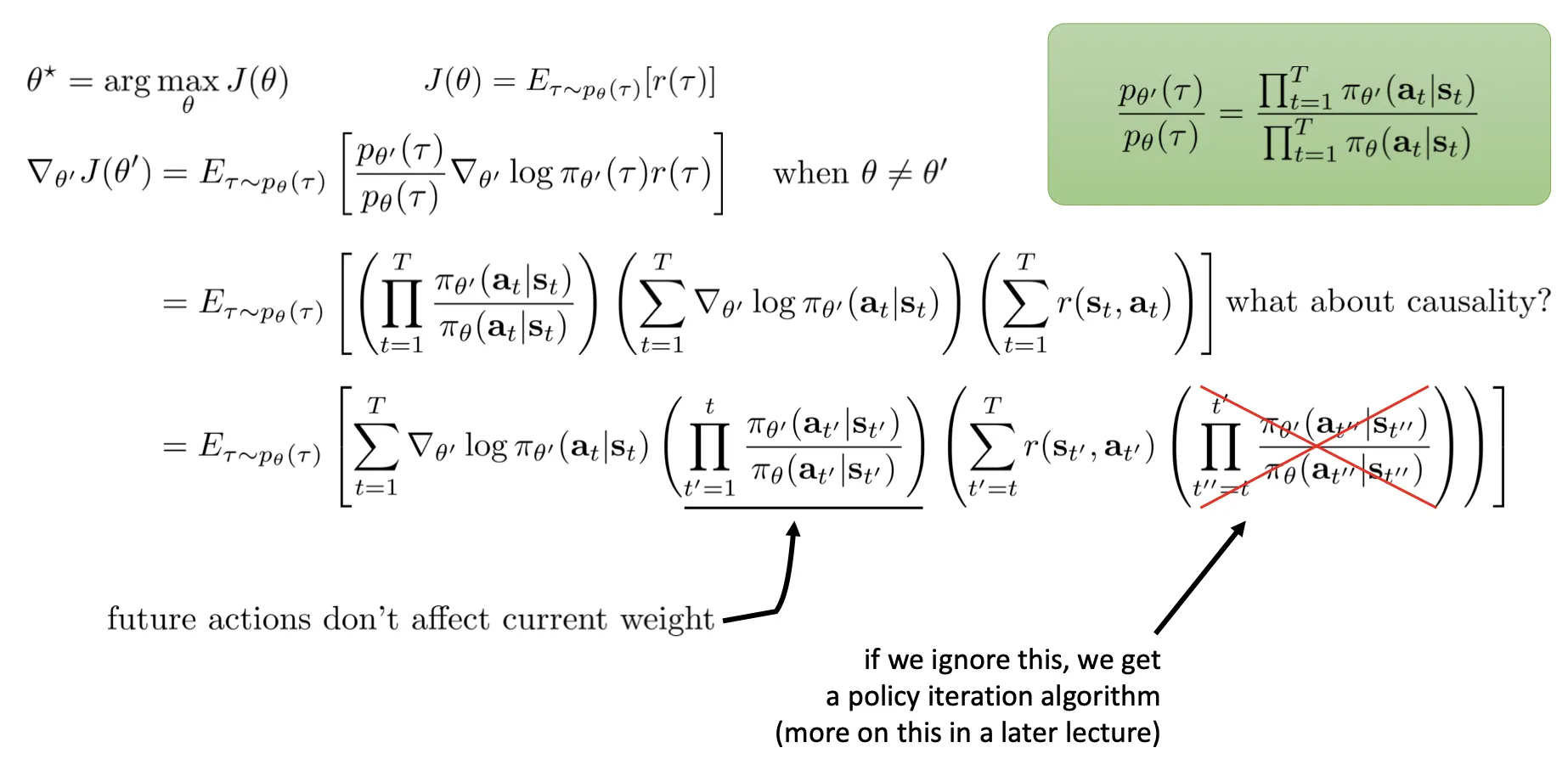
2 Editing Code
如何可视化: tensorboard --logdir=/home/julyfun/Documents/GitHub/homework_fall2023/hw1/data/q1_bc_ant_HalfCheetah-v4_2 3-11-2025_00-00-06/
“
- Ant-v4:
1Eval_AverageReturn : 4795.38281252Train_AverageReturn : 4681.8916739358163Training Loss : 0.0011749982368201017- Walker-2d 只有 2d 物理
1Eval_AverageReturn : 998.9587402343752Train_AverageReturn : 5383.3103251776683Training Loss : 0.01655399613082409走的不太行,能往前冲一点
- HalfCheetah
1Eval_AverageReturn : 4070.51464843752Train_AverageReturn : 4034.79998349650673Training Loss : 0.004244370386004448
- Hopper
1Eval_AverageReturn : 1542.3718261718752Train_AverageReturn : 3717.51299361823073Training Loss : 0.010719751007854939看视频跳的还可以
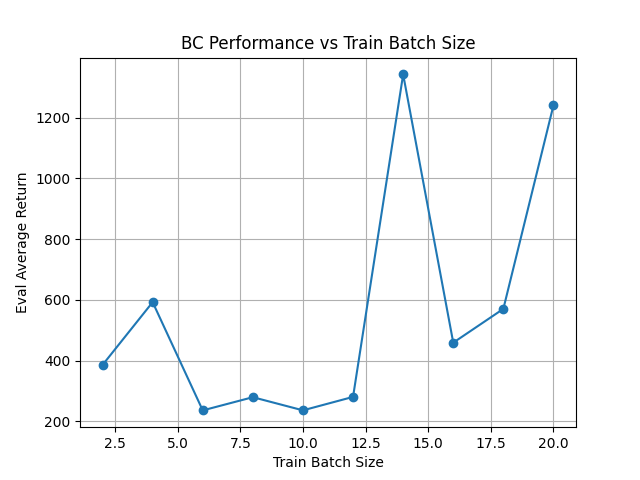
 关于这个 Hopper 任务, batchsize: (我本来还想搞 N 条轨迹来实验,但是这个专家数据只有若干个 s-a pair,没法搞)
关于这个 Hopper 任务, batchsize: (我本来还想搞 N 条轨迹来实验,但是这个专家数据只有若干个 s-a pair,没法搞)

3. Dagger
- 任务是 Walker-2d
- 这里
batch_size default=1000参数不用调,因为 train 的时候只拿出前train_batch_size=100个. 是公平的.
1Eval_AverageReturn : 998.9587402343752Eval_StdReturn : 488.84045410156253Train_AverageReturn : 5383.3103251776684Train_StdReturn : 54.152515638717895Training Loss : 0.016553996130824096
7********** Iteration 1 ************8Eval_AverageReturn : 5408.24316406259Eval_AverageEpLen : 1000.010Train_AverageReturn : 1130.50415039062511Train_StdReturn : 583.066223144531212Training Loss : 0.02255682088434696213
14********** Iteration 2 ************15Eval_AverageReturn : 5389.767089843754 collapsed lines
16Eval_StdReturn : 0.017Train_AverageReturn : 5411.1459960937518Train_StdReturn : 0.019Training Loss : 0.012993226759135723-
实验时在默认命令上尽量少改动.
-
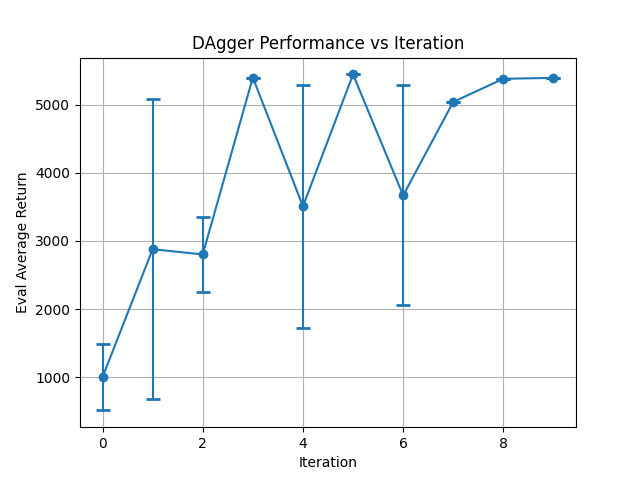
Walker2d DAGGER:
-
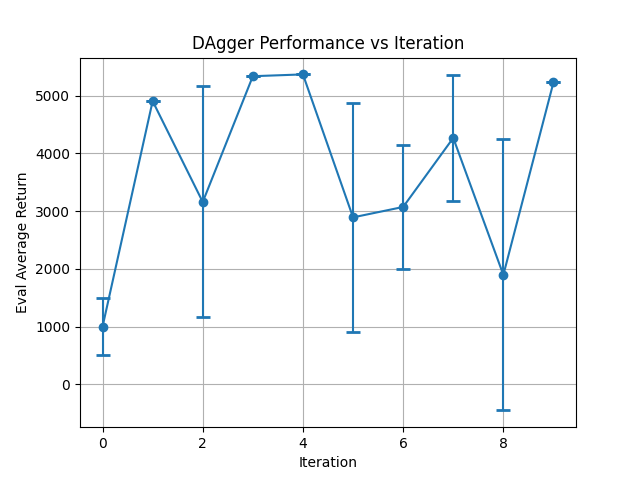
强制不收集新数据:
if itr == 0:=>if itr == 0 or True:(后来我改了其他代码,可以 no_dagger 多轮执行) -
no-dagger Step 0: 会 terminate
-
DAgger Step 9:
-
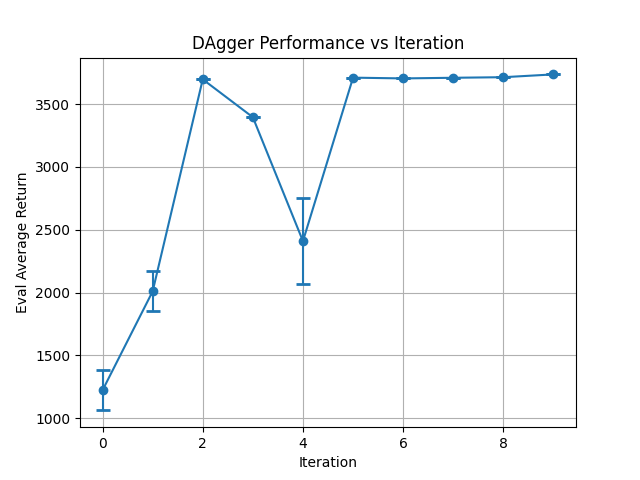
Hopper DAgger:
-
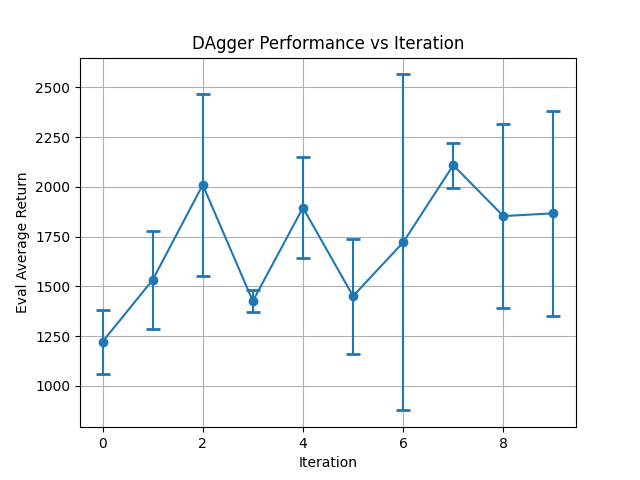
Hopper no dagger
-
DAgger Step 9: