InSpire (27)
⭐️⭐️ 同济 Ji Zhang, Jingkuan Song | https://koorye.github.io/Inspire/ | https://arxiv.org/pdf/2505.13888
在 Pi0 基础上直接对 VLM 输入“物体在哪里” 作为 aux task 并且也会把输出结果直接再次输入 VLM.
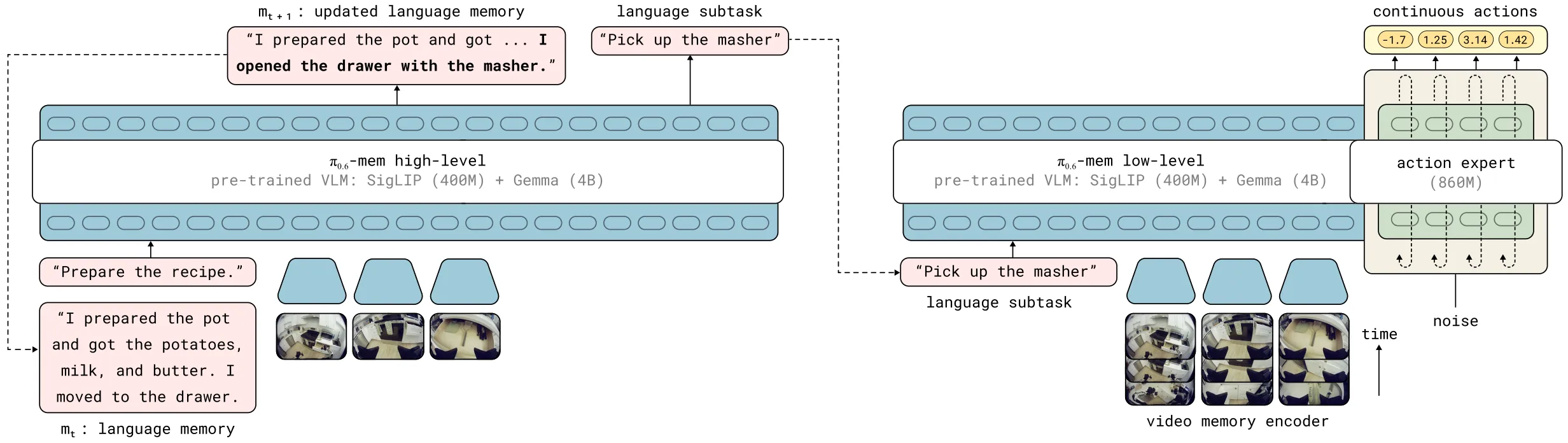
MEM (28)
⭐️⭐️⭐️ PI 团队
直接复制一个 pi0.5 的 VLM 作为 system 2 来做 text-level 长时序总结,而 system 1 改用 video 输入达到短时序能力.
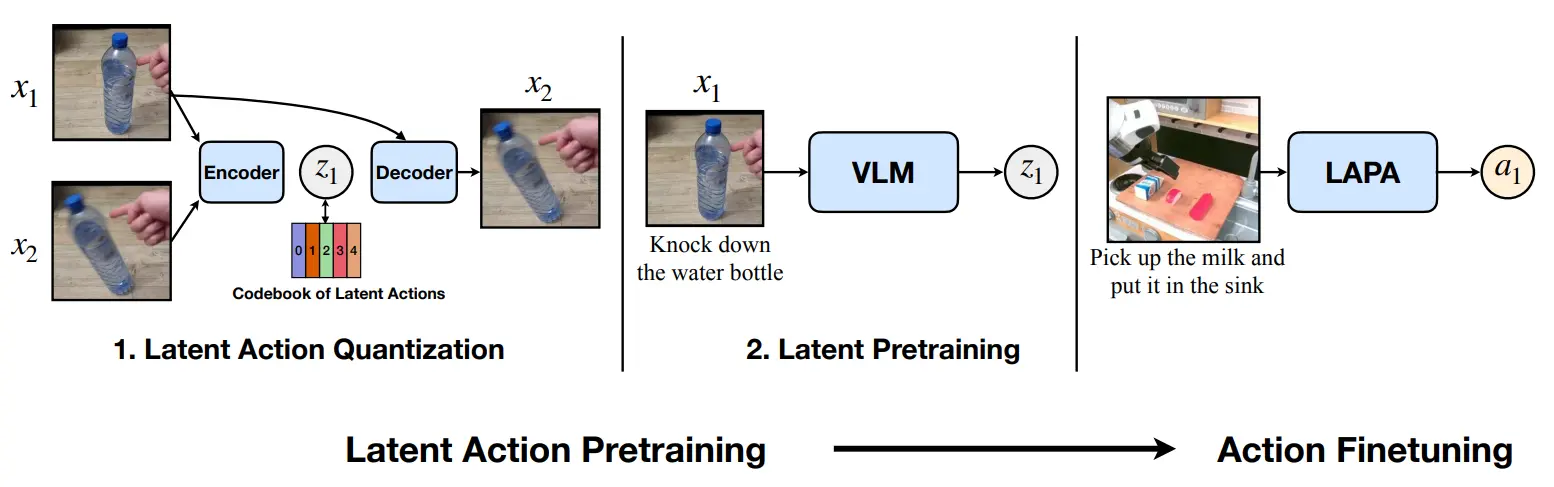
LAPA (29)
⭐️⭐️⭐️ https://hjfy.top/arxiv/2410.11758
自监督在相邻帧训练 IDM -> latent_token -> FDM 模型,作为 VLM 的 pretraining label.
3 步训练:
- 自监督利用互联网视频训练一个 encoder: (x1, x2) -> z(VQ 离散化)和 decoder: (x1, z) -> x2,这类似于 IDM 和 FDM. 这里 x1 和 x2 相差 T 帧.
- 监督 Latent Pretraining: 利用上面模型打 label,然后给 VLM 接入一个新的 latent head,输入 x, l 输出 z
- Action FT: 给 VLM 接入 action head,输入 x, l 输出 action
当然,对于 ego 视频来说画面的变化无法实际上完全用 z 解释,因素还有视角变化和物体运动等,因此这一套自监督不算很完备.
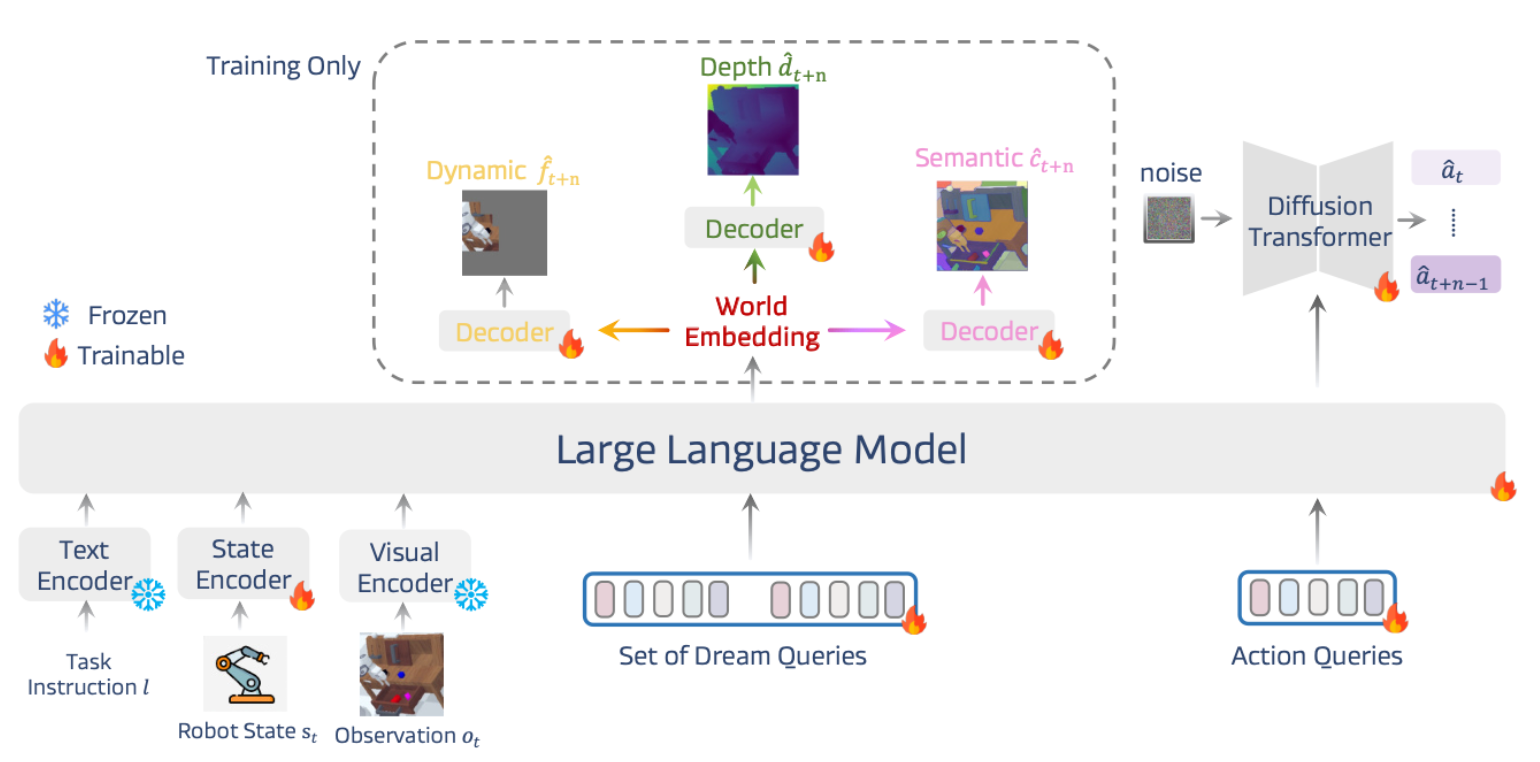
DreamVLA (30)
⭐️⭐️ 上交 wenyao zhang, EIT Xin Jin | https://hjfy.top/arxiv/2507.04447
相比普通 WM,本文预测的不是 video latent 而是自定义的 world latent,train-time tasks 包括未来的动态区域、深度、DINO-V2 emb 等. infer-time 使用此 world latent 作为 action query 的 kv.
Lingbot-VLA (31)
⭐️⭐️ https://hjfy.top/arxiv/2601.18692
在 pi0 基础上增加了一条 learnable depth query -> [VLM (attend to image token)] -> [a new proj] -> depth token 的监督,并增大数据到 20000h. 此外,使用了 FSDP 和 FlexAttention 提升吞吐量.
MemoryWAM: Efficient World Action Modeling with Persistent Memory (32)
⭐️⭐️⭐️ 用近期帧、起始帧和 gist tokens 来压缩长期记忆 [香港中文大学,Sizhe Yang,Huazhe Xu]
| https://yangsizhe.github.io/MemoryWAM/ | https://hjfy.top/arxiv/2606.20562 | https://www.alphaxiv.org/abs/2606.20562 | https://github.com/yangsizhe/MemoryWAM |
|---|
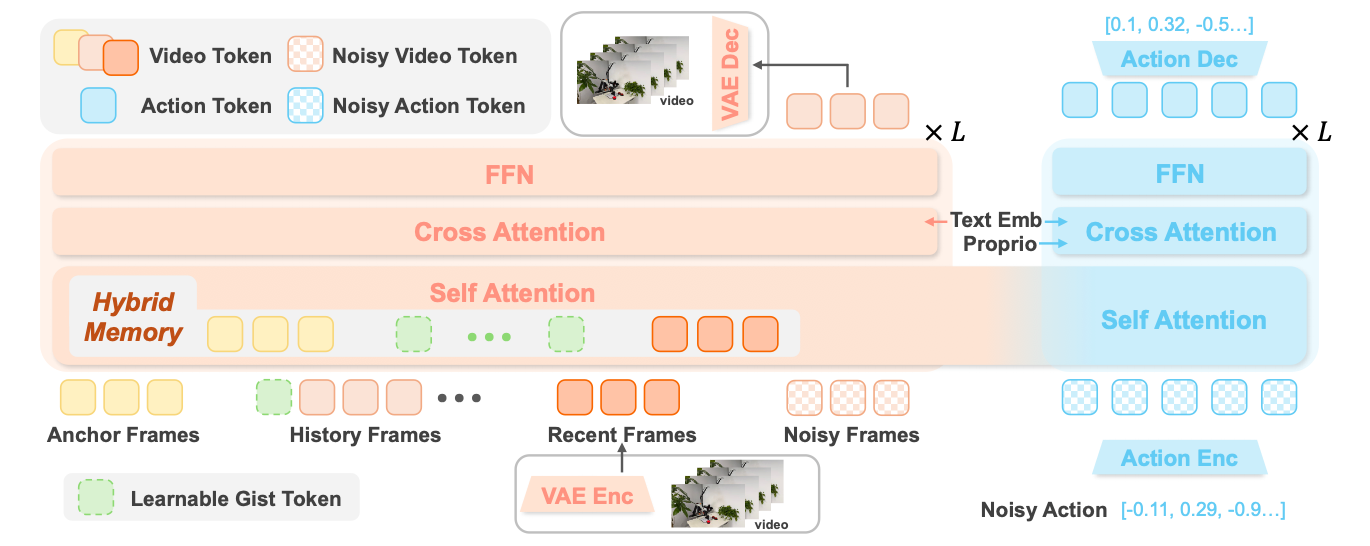
- 所有帧共享 8 个 learnable gist query embedding[1],这样就可以每帧留下 8 个 gist embed 和对应 kv cache.(完整视觉 token 是 120 个).
- 滑动窗口完整视觉 token
- 起始帧完整视觉 token
其他结构则是 Pi-like Video DiT + action expert DiT.
- 别忘了 query embedding 需要经过 W_q 才会得到真正 query.
DiT4DiT (33)
⭐️⭐️ [YY 硕]
| https://dit4dit.github.io | https://hjfy.top/arxiv/2603.10448 |
|---|
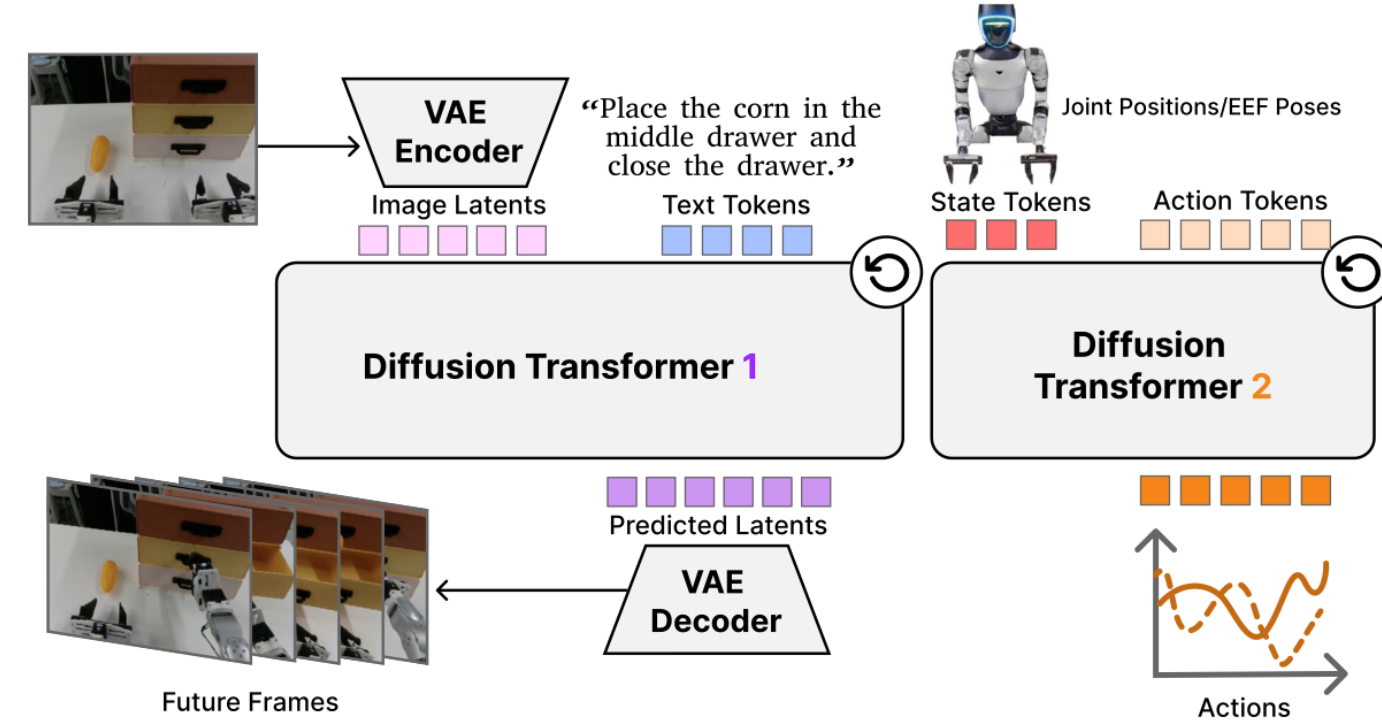
一种正常的 Joint WAM. demo 的全身控制在论文中并没有提及,实际上代码中直接封装了 Nvidia GR00T-WholeBodyControl 并且让 model 直接输出 29 dof,数据则通过 Pico 4 直接采集,通过摇杆控制左右上下运动.
GR00T WBC 对于上身指令直接发给电机,下身指令则提取意图后接入 RL MLP.
π₀.₇ pi0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities (34)
⭐️⭐️⭐️ 添加 subgoal image, memory 和 quality tag. [Physical Intelligence,Bo Ai]
| https://pi.website/pi07 | https://hjfy.top/arxiv/2604.15483 | https://www.alphaxiv.org/abs/2604.15483 | https://github.com/Physical-Intelligence/openpi |
|---|
给 VLM 的输入添加了:
- MEM-style[注] memory.
- 由 BAGEL WM 在 subtask 切换或者超过 4 秒后生成 subgoal image,经过 image encoder 送给 VLM.
- quality, mistake 等标签类似于 pi0.6,在 infer-time 设定 quality=5 直接拼接到 text prompt 中,提供利用失败轨迹的方法.
MEM-style:
- 长期记忆用 text.
- 短期记忆用 video encoder,输入 [B, K=历史帧数, N=patch数量, D],每帧 causal temperol 注意之前的帧,最后保留当前帧 [B, N, D].
FiLM: 把 cond 投影成 x per-channel 的 scale 和 bias.
1x: (B, C, D) cond: (B, cond_dim)2# ╰ channels3cond = linear(cond) # (B, 2 * C)4scale, bias = cond[:, 前一半], cond[:, 后一半]5x = scale * x + biasGenerating Robot Hands from Human Demonstrations
| [Gemini 3.1 Pro] 利用人类手指运动轨迹,通过逆运动学直接优化并生成机器手硬件设计 | <加州大学圣地亚哥分校,Sha Yi,Xiaolong Wang> | https://yswhynot.github.io/generating-robot-hands/ | https://hjfy.top/arxiv/2606.20549 | https://www.alphaxiv.org/abs/2606.20549 |
|---|
本文将逆运动学作为固定策略,联合优化机器手硬件参数和关节轨迹以拟合人类手指的运动轨迹。为了加速搜索,本文训练了一个 RL actor 来输出硬件设计和关节初始值,随后再用梯度下降进行微调。可以用来参考如何将人类运动数据用于机器人的形态协同设计。 本文目前只优化拇指和食指的指尖位置,没有考虑全手接触和受力情况,且 3D 打印的结构在承受高负载时容易损坏。
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
| [Gemini 3.1 Pro] 提出 M2Flow 范式解耦逻辑工作流与物理调度,构建高灵活度的大规模强化学习并行训练系统 | 清华大学, Chao Yu, Yu Wang | https://hjfy.top/arxiv/2509.15965 | https://www.alphaxiv.org/abs/2509.15965 | https://github.com/RLinf/RLinf |
|---|
RLinf 允许开发者直接用代码定义大模型强化学习组件交互,随后系统会自动分析性能并搜索出最优的时空流水线配置。它在底层原生支持自动上下文切换和自适应通信机制,复现时可以直接运 行官方开源框架来训练模型。
系统采用的动态规划调度强依赖基于多项式外推的预先性能剖析,这种预估方式在极端动态长尾负载下可能产生时间计算误差,进而降低自动分配流水线的实际并行效率。