https://hrl.boyuai.com/chapter/2/策略梯度算法/
-
之前的算法基于价值,没有显式策略(策略就是选最大动作价值的动作)。下述 REINFORCE 方法基于策略.
-
设 是策略,处处可微,要学习的参数为
-
目标是最大化 :
-
设状态访问分布为 (无穷步状态概率加权向量,见第三章),有:
- 提示:

-
另一证明:
- https://paddlepedia.readthedocs.io/en/latest/tutorials/reinforcement_learning/policy_gradient.html
- 此图第一行少写了一个
- 这里 是执行 后转移到 的概率.
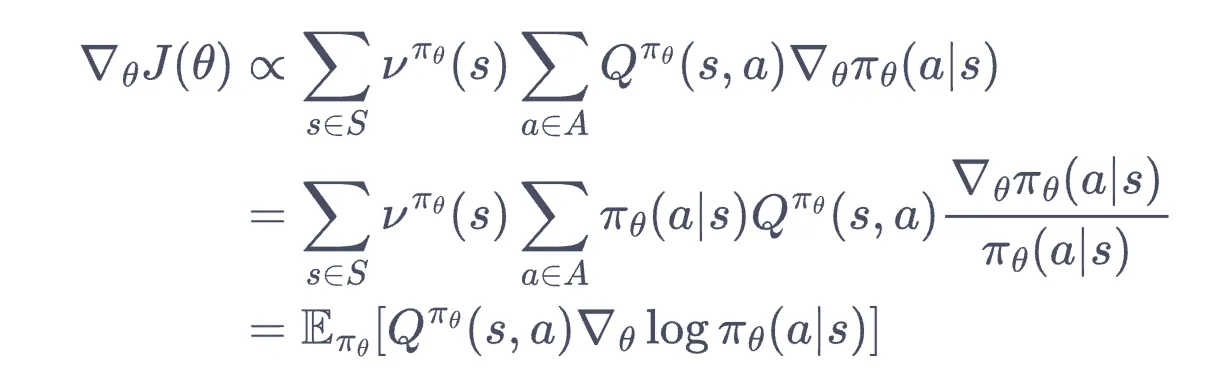

蒙特卡洛 REINFORCE
-
考虑用蒙特卡洛方法估计,对有限步的环境来说,依据上式有:
- 其中 为最大步数. 小括号内就是 ,下面第二张图中以 表示.
-
训练步骤
-
网络结构:
- Input: 可微状态
- Output: 离散动作的概率多项分布
- 损失函数: 上述梯度更新公式(去掉微分符号)
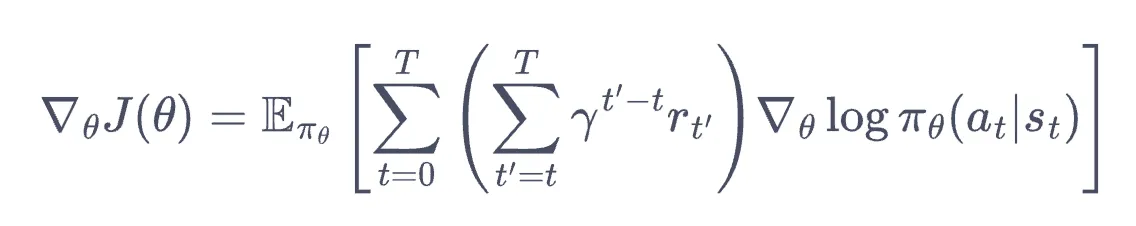

1class PolicyNet(torch.nn.Module):2 def __init__(self, state_dim, hidden_dim, action_dim):3 super(PolicyNet, self).__init__()4 self.fc1 = torch.nn.Linear(state_dim, hidden_dim)5 self.fc2 = torch.nn.Linear(hidden_dim, action_dim)6
7 # 输入当前状态,输出各个可选动作的概率分布, 例如 [0.3, 0.7]8 def forward(self, x):9 x = F.relu(self.fc1(x))10 return F.softmax(self.fc2(x), dim=1)11
12class REINFORCE:13 def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,14 device):15 self.policy_net = PolicyNet(state_dim, hidden_dim,82 collapsed lines
16 action_dim).to(device)17 ...18
19 def take_action(self, state): # 根据动作概率分布随机采样20 state = torch.tensor([state], dtype=torch.float).to(self.device)21 probs = self.policy_net(state)22 action_dist = torch.distributions.Categorical(probs)23 action = action_dist.sample() # 随机选一个24 return action.item()25
26 def update(self, transition_dict):27 # 一个 list 即是开始到 done 所有步骤28 reward_list = transition_dict['rewards']29 state_list = transition_dict['states']30 action_list = transition_dict['actions']31
32 G = 033 self.optimizer.zero_grad()34 for i in reversed(range(len(reward_list))): # 从最后一步算起35 reward = reward_list[i]36 state = torch.tensor([state_list[i]],37 dtype=torch.float).to(self.device)38 action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device)39 # 这里仅仅是提取rollout过程中采纳那个 action 的概率.40 # 这个概率也是最终 loss 中唯一的梯度来源. 其他 action 的可能回报在这里不产生影响.41 log_prob = torch.log(self.policy_net(state).gather(1, action))42 G = self.gamma * G + reward43 loss = -log_prob * G # 每一步的损失函数44 loss.backward() # 反向传播计算梯度45 self.optimizer.step() # 梯度下降46
47# 其他一样.48learning_rate = 1e-349num_episodes = 100050hidden_dim = 12851gamma = 0.9852device = torch.device("cuda") if torch.cuda.is_available() else torch.device(53 "cpu")54
55env_name = "CartPole-v0"56env = gym.make(env_name)57env.seed(0)58torch.manual_seed(0)59state_dim = env.observation_space.shape[0]60action_dim = env.action_space.n61agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,62 device)63
64return_list = []65for i in range(10):66 with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:67 for i_episode in range(int(num_episodes / 10)):68 episode_return = 069 transition_dict = {70 'states': [],71 'actions': [],72 'next_states': [],73 'rewards': [],74 'dones': []75 }76 state = env.reset()77 done = False78 while not done:79 action = agent.take_action(state)80 nexth_state, reward, done, _ = env.step(action)81 transition_dict['states'].append(state)82 transition_dict['actions'].append(action)83 transition_dict['next_states'].append(next_state)84 transition_dict['rewards'].append(reward)85 transition_dict['dones'].append(done)86 state = next_state87 episode_return += reward88 return_list.append(episode_return)89 agent.update(transition_dict)90 if (i_episode + 1) % 10 == 0:91 pbar.set_postfix({92 'episode':93 '%d' % (num_episodes / 10 * i + i_episode + 1),94 'return':95 '%.3f' % np.mean(return_list[-10:])96 })97 pbar.update(1)- 考虑最优情况的正确性:若 ,则会学到使得 尽可能大(取 -log 后尽可能小,损失尽可能小), 尽可能小(取 -log 后极大,损失极小)
- softmax 应该能防止数值爆炸.
优化问题,神经网络和强化学习
…