Lec6 Actor Critic
- 为什么加入 baseline 项可以减少方差呢?
- 因为 Q(s, a) - V(s) 可以分离出动作 a 本身的价值,降低梯度波动.
- 我们发现 A(优势函数)只需要 fit V, 因为 A =
r + V(s_(t+1)) - V(s_t)
- 如何定义 呢? 有下图两种公式,其中第二个公式更好,但是这需要从同一个 出发多次采样,除了仿真以外是不可能的!
- 所以我们采用图中第一个公式.

- 于是我们有了第一个训练 critic 的方法:
- 下一步:我们也可以直接用 V 估计之后的收益,尽管训练一开始估计很不准. 这就是 temporal difference 或者说 bootstrap.
- td 方法具有 Lower variance, Higher bias. (“because it’s using b_hat instead of a single sample estimator”, 或者说 是一个期望而不是一个采样. )
- GAE(Generalized Advantage Estimation) 方法:用多步 td 代替单步 td.
- off-policy: 具体查看 10-actor-critic算法.
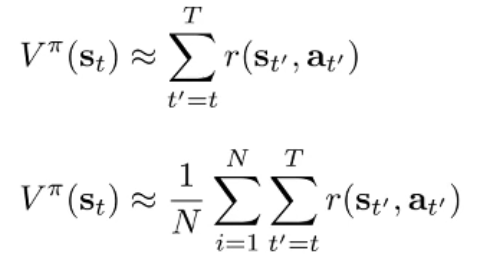
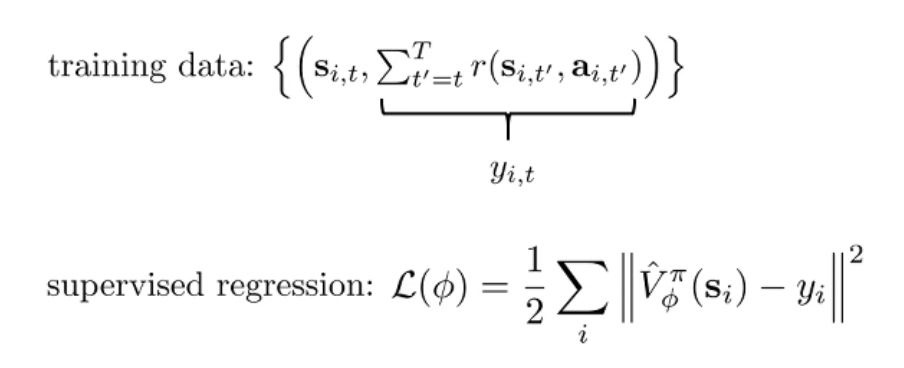
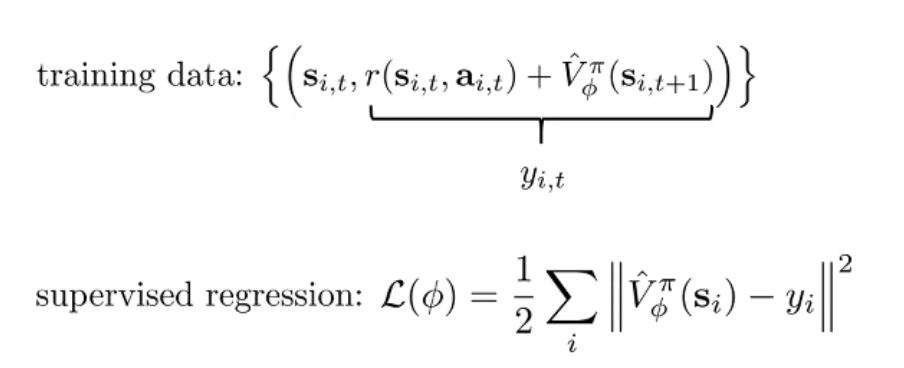
Lec7 Value-based RL 即 Q-learning
- 我们直接把 actor-critic 算法的 a 设定为选择 Q(s, a) 最大的 a(概率为 1,其他概率为 0). 这样就不用训练 actor 了,直接去除了 Policy-Gradient,因此可以使用离线 replay-buffer,只要 (s, a) 非常丰富并且 Q 拟合得够好就能 work.
- 可能会遇到贪心永远走老路的问题,因此可使用 epsilon-greedy(1 - epsilon 概率随机动作)或者 boltzmann 探索(按照 Q 大小选择动作)
- 这种 Q-learning 仅支持离线,因为你只有 Q(s, a),离散动作下枚举即可获得最优动作,连续动作下你会无法求出哪个 a 是最优的,连动作都没法选.
- 这种写法不 work(根据目标函数更新完 Q 参数也相当于改变了目标函数,导致在目标附近来回震荡),我们来看下一章如何优化.
Lec8 Q-learning in practice
- DQN’s target-network 方法: 复制一份 Q2 目标网络不更新参数只算 y = r(s, a) + gamma * Q2(s’, a’),每隔 10000 步同步一次(或者 polyak 方法:每次按 0.001 缓慢更新权重). 原来的网络 Q1 则与环境互动并存数据.
- 通过离线 replay buffer 采样更好,因为在线交互的 (s, a) 分布与 Q 相关性太强,容易导致训练震荡.
- n-step 技巧:连续计算后面 N 步奖励衰减求和。
- 逐渐降 epsilon 探索率.
- huber 损失:误差小时依然用 mse,误差大时改用绝对值.
- 更强的方法:Double DQN. 用的仍然是原来两套网络.
1# DQN2# 从 replay buffer 中采样多个 (s, a, r, s_next, done)3a_next = argmax_a Q_target(s_next, all a)4y = r + gamma * Q_target(s_next, a_next) # Q_target 方差会导致 y 期望增高,Q_online 对该动作的期望也偏高,后续还更可能选它5loss = mse(Q_online(s, a), detach(y))67# Double DQN8a_next = argmax_a Q_online(s_next, all a) # 训练网络选动作9y = r + gamma * Q_target(s_next, a_next) # 目标网络评估动作. 此时 Q_online 的方差不会引起 y 期望偏高10loss = mse(Q_online(s, a), detach(y))
在传统的 DQN 算法中,本来就存在两套函数的神经网络——目标网络和训练网络(参见 7.3.2 节),只不过的计算只用到了其中的目标网络,那么我们恰好可以直接将训练网络作为 Double DQN 算法中的第一套神经网络来选取动作. (- 动手学强化学习)
即使 Q_online 因正误差选中了某个动作,Q_target 对同一个动作的估计不一定也正好虚高,所以 target 不会系统性地总取到最大正误差。(- GPT5.5)
- DDPG: 结合 Soft Actor-Critic 和 DQN(分离评分网络和被更新网络),一共有四个网络. 但由于 actor 的引入,并不需要 double-DQN 技巧.
1replay_buffer.add(s, a, r, s2, done)2states, actions, rewards, next_states, dones = replay.sample() # 数据可能来自旧 policy3with no_grad():4 next_actions = pi_target(next_states) # 这一步也是为了评分. 在 285 HW3 中,这里使用了 online_actor,因此一共是3个网络5 td_target = rewards + gamma * Q_target(next_states, next_actions) * (1-dones)6# 更新 critic7critic_loss = mse(Q_phi(states, actions), td_target)8critic_optim.zero_grad()9critic_loss.backward()10critic_optim.step()11# 更新 actor12freeze(Q_phi)13actor_loss = -mean(Q_phi(states, pi_theta(states)))14actor_optim.zero_grad()15actor_loss.backward()4 collapsed lines
16actor_optim.step()17# 软更新 target networks (e.g. tau = 0.999)18soft_update(pi_target, pi_theta, tau)19soft_update(Q_target, Q_phi, tau)- 为什么 deep Q-learning 难收敛的数学理解: 表格型 q-learning 可以直接执行
Q <- BQ,此处 B 为贝尔曼最优算子,其为 (最大同维差)上的压缩映射,全局最大误差一定乘 gamma 会不断缩小. 但多了神经网络以后多了投影算子Q <- ΠBV,即在神经网络能够表达的函数集合 Ω 中找一个 V_ϕ 使得 V_ϕ 和 BV 的 L2 误差最小. 而ΠB不再是压缩映射,导致 DQN 天然不稳定.
Lec9 Off-policy policy gradient
注意:AC 其实一直使用的是 wrong advantage 和 wrong state distribution,具体查看 10-actor-critic算法 的 on-policy 注释.
- IS: 考虑离散动作 on-policy actor-critic,要改为 off-policy 则从 replay buffer 中取出用于更新时额外乘
pi_new(a|s) / pi_old(a|s)即可. 但这里有 BUG: 如果pi_old(a|s)接近 0,权重会爆炸. - PPO (Proximal 近端 Policy Optimization): 裁剪重要性权重到 范围内,例如
0.8 ~ 1.2. 此外,PPO 还采用了 GAE loss 以及熵正则 loss(鼓励策略多探索).1# TD loss: 单步即可2target = r + gamma * V(s2) * (1 - done)3loss = mse(V(s), detach(target))45# 蒙特卡洛 loss: 需要整条轨迹倒序递推6G_t = r_t + gamma*r_{t+1} + gamma^2*r_{t+2} + ...7loss = mse(V(s_t), detach(G_t))89# GAE loss: 也需要整条轨迹倒序递推 (A_{t+1})10# λ≈0.95,用于平衡 bias 和 variance, lambda 大则 variance 高 bias 小.11delta_t = r_t + gamma * V(s_{t+1}) - V(s_t)12A_t = delta_t + gamma*lambda*A_{t+1}13loss = mse(V(s_t), detach(A_t + V(s_t)))
Lec10 Advanced Policy Gradient
- 关于上面提到的 PPO,我们还希望让训练更稳定。
- 加一个 KL loss(在输出的 action prob 上,KL(π_old ‖ π_new)),注意不是 entropy.
- 直接限制新旧 action prob 变化概率比值在 范围内. 这个更常用. 但 PPO 是在网络参数上更新的,怎么限制输出概率变化的? 其实并不能硬限制参数,而是在 importance sampling 中限制,避免奖励过大.
1# 采样时保存:old_log_probs = log(pi_old(states)[actions])2states, actions, rewards, next_states, dones, old_log_probs = replay.sample()3td_target = rewards + gamma * V_phi(next_states) * (1 - dones)4td_delta = td_target - V_phi(states)5advantages = detach(td_delta)6log_probs = log(pi_theta(states)[actions])7ratio = exp(log_probs - old_log_probs) # ratio 即为 pi_theta(a|s) / pi_old(a|s)8unclipped = ratio * advantages9clipped = clip(ratio, 1 - epsilon, 1 + epsilon) * advantages10actor_loss = -mean(min(unclipped, clipped))11critic_loss = mse(V_phi(states), detach(td_target))Lec11
- 引出了隐变量(先验分布为正态分布)和 vae.