https://rail.eecs.berkeley.edu/deeprlcourse-fa23/
- hw1: https://rail.eecs.berkeley.edu/deeprlcourse-fa23/deeprlcourse-fa23/static/homeworks/hw1.pdf
- hw2:
- 讲师:Sergey Levine https://people.eecs.berkeley.edu/~svlevine/ (some talks here)
FAQ
何时来的?

- 从右往左看.
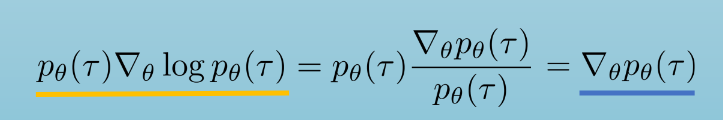
导数怎么传递到 上的?
- Q-learning 是 (s, a) r,这里 s,a,r 都在数据集中,所以就是监督学习
符号
-
: 策略的累积奖励的期望,需要最大化
-
顺序:
-
: 轨迹,表示所有
-
:状态 下采取 的概率
-
状态价值函数 state-value function,即还不确定
-
动作价值函数 action-value function,即确定了
- 有
强化学习类型
- Policy Gradient: 求 对 的导数.
- 训练:
- Actor: 输入
[机械臂状态,观测] - 输出
[动作]或者[动作的概率分布]
- Actor: 输入
- 推理: 一样
- 训练:
- Actor-Critic: 有 A 有 Q
- Model-based: 有模型自行估计 经过 如何转移 ( learn )
On-off policy
- off-policy: able to improve the policy without generating new samples from that policy
- on-policy: any time the policy is changed (even a little bit) we need to generate new samples.
- (and there is offline-RL, which runs on a fixed dataset and rollout is not allowed)
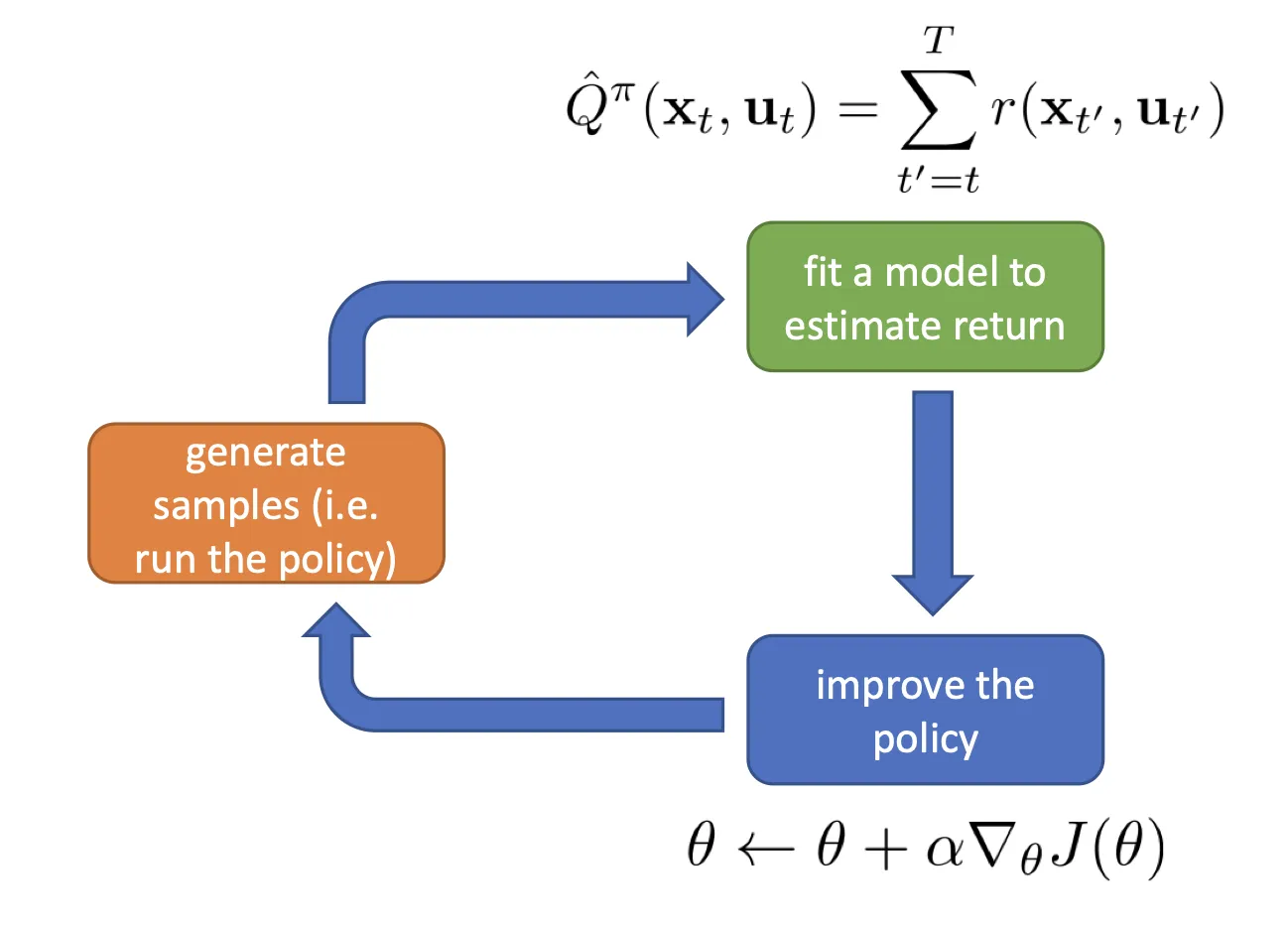
Lec5 Policy Gradients
- https://rail.eecs.berkeley.edu/deeprlcourse-fa23/deeprlcourse-fa23/static/slides/lec-5.pdf
- Maximum likehood 仅仅让 朝着“这批动作出现概率最大”的方向演进.
- 问题:奖励方差大,训练效率低下。好轨迹梯度可能为 0(累积奖励 0),有效奖励信号丢失.
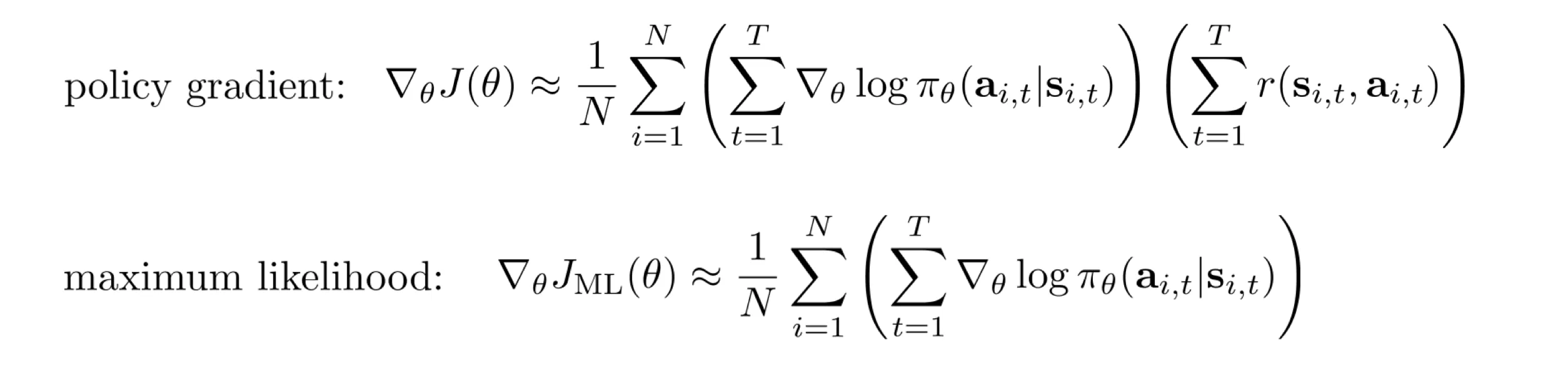
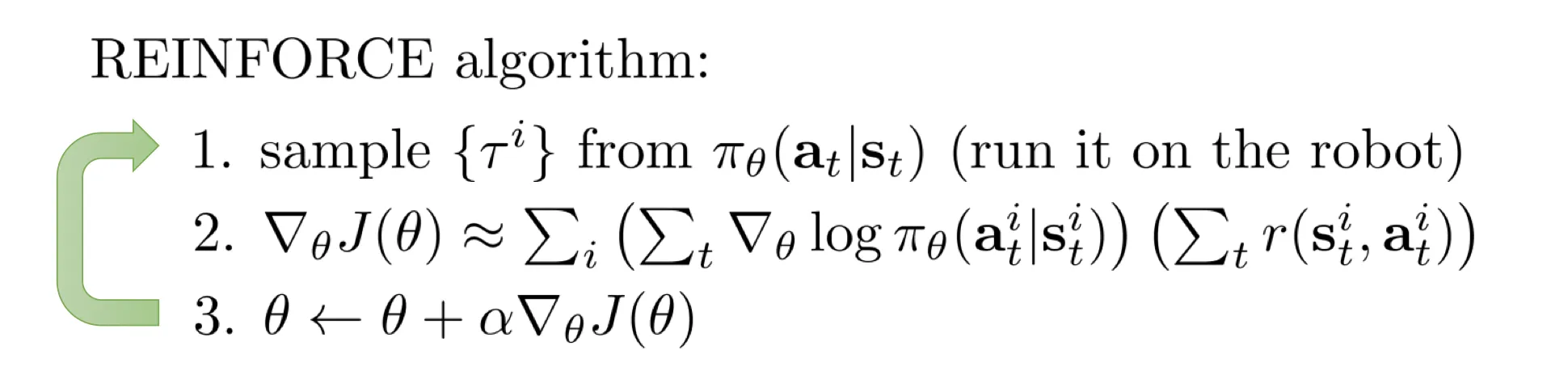
例子:高斯 policy
这里距离是马氏距离,用协方差使得距离评估更准.
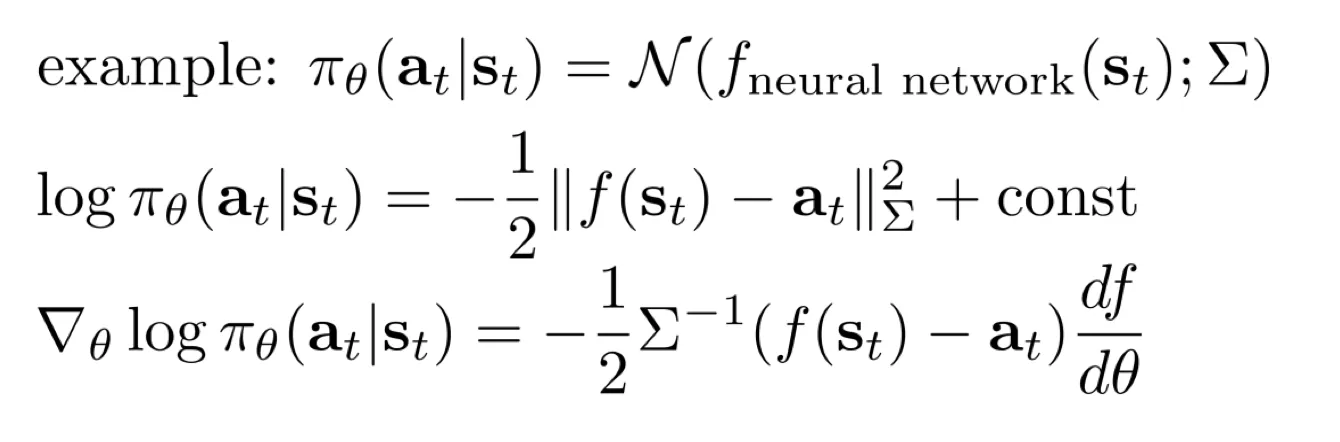
两种优化
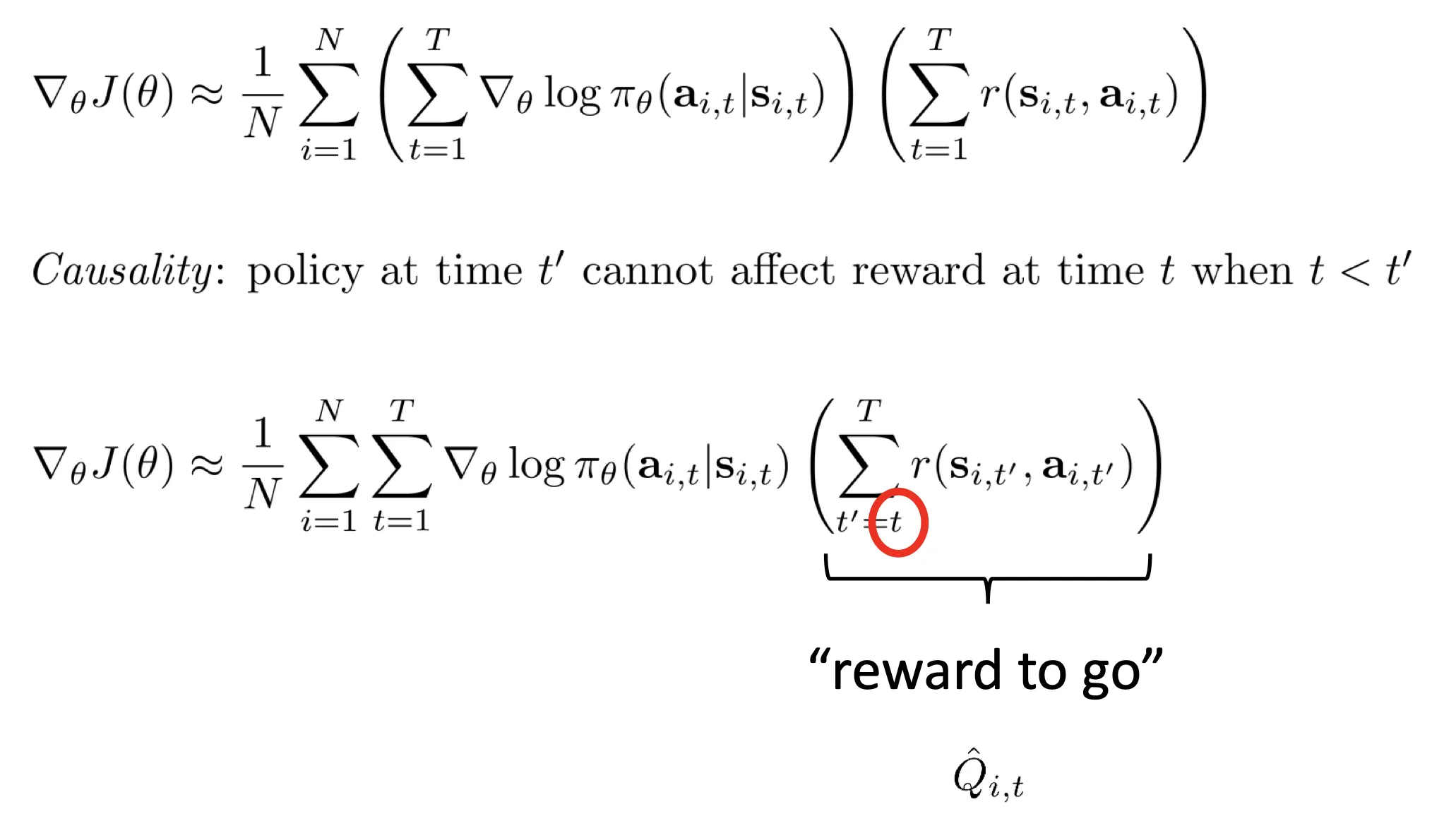
- 换种形式: reward to go:
- 等等先换一个话题,我们求一个 baseline 并改写奖励为
,目的是使梯度方差最小。推导出最优的 为:
- 其中:
- 结合以上两个优化,得到:
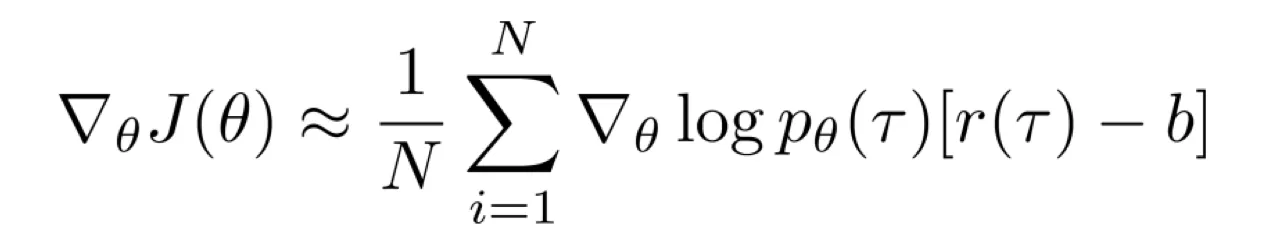 ,目的是使梯度方差最小。推导出最优的 为:
,目的是使梯度方差最小。推导出最优的 为:
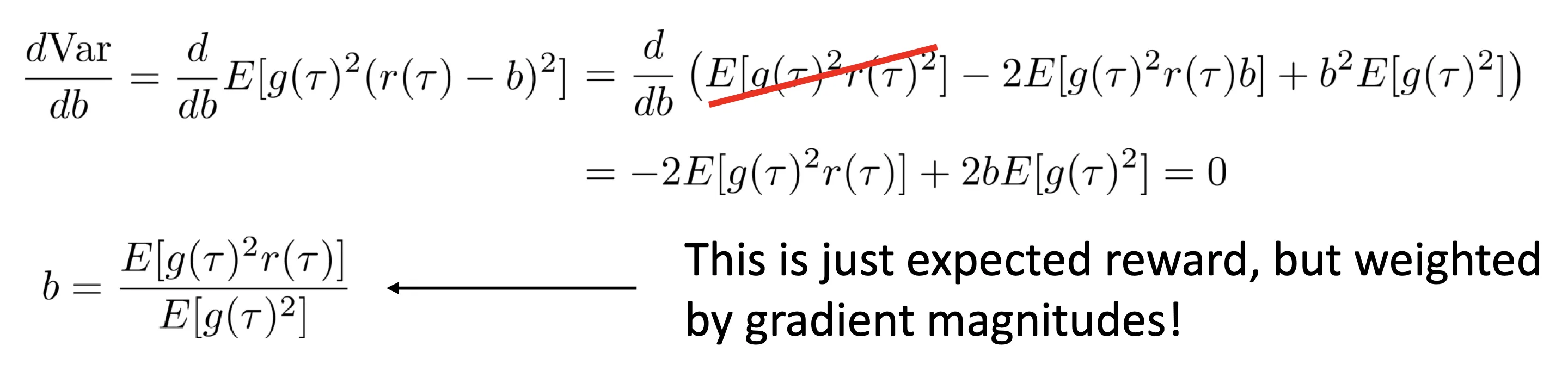
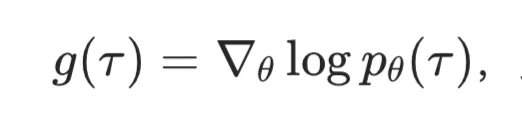
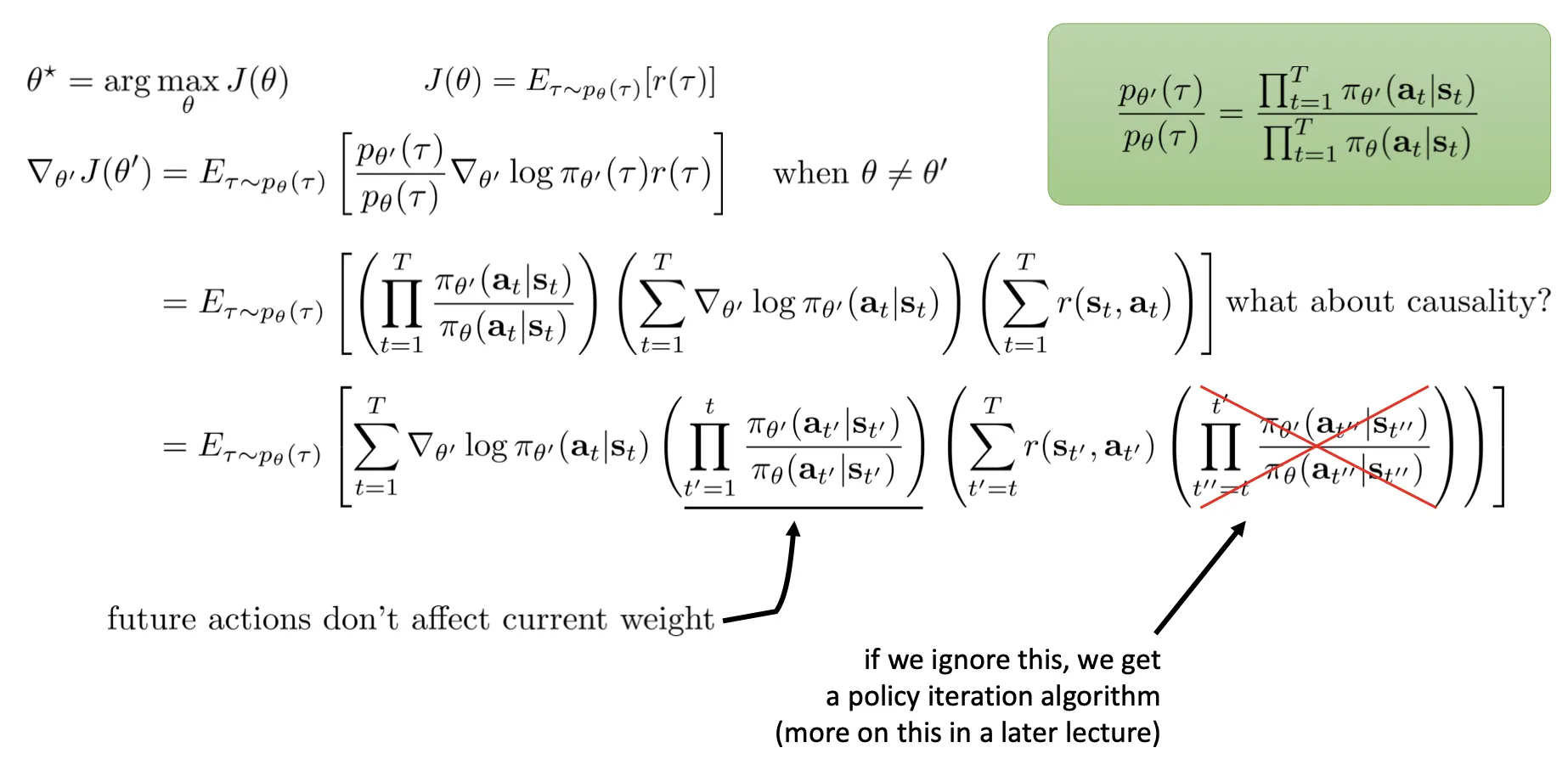
为什么 PG 必须是 on-policy
- 可以理解为:上述 “REINFORCE algorithm” 公式是对 求导, 必须是最新的,求的梯度才有意义。这导致训练效率很低. 当然你可以多采样几次,相当于 batch 大很多.
- 或者理解为:采集的 (s, a, reward-to-go) 序列其实是 conditioned on policy 的. 比如 policy 现在的特性是走路径(1)收益很大,但是在历史轨迹中走 (1) 的收益很低,走路径 (2) 的收益很大,那么 PG 会学习走路径(2),就学错了.
importance sampling
- 这个公式就是 IS:
- [ok]
- [grep] 注意上图 那个概率在下图这里已经改写为乘积完毕的形式 .
- 最后还是改用自动求导了,因为显示计算 那一项开销太大. 而 那一项正好对应平方误差.
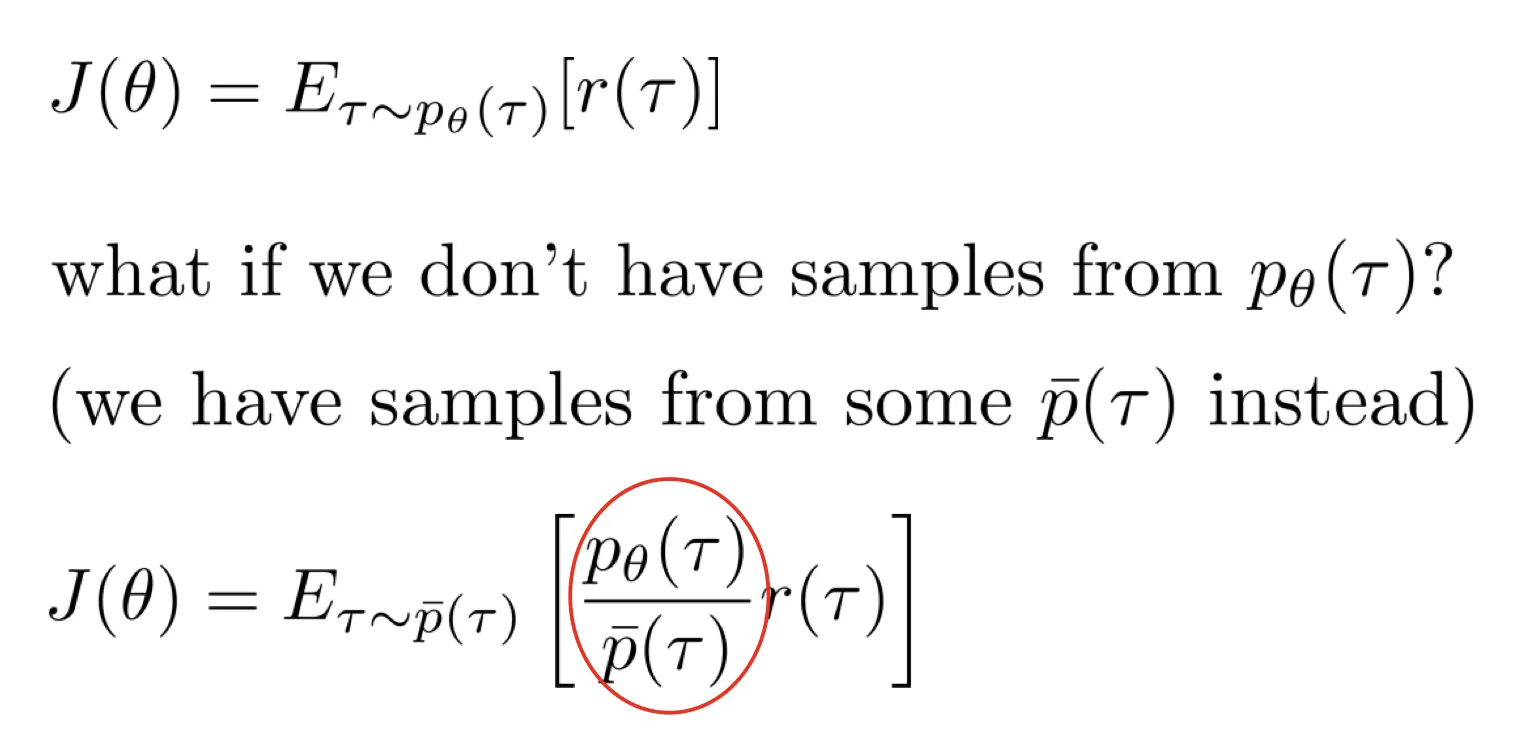

优化的梯度下降?
- 能直接走到最好的 吗?
- 上图第一个方法“参数距离约束”依赖于参数的具体形式,不好。
- 上图 KL 散度: 通过采样计算.

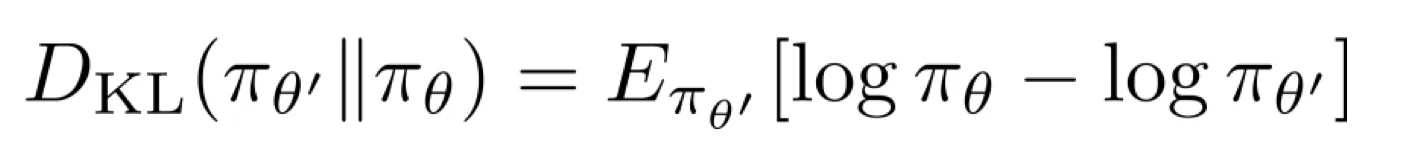 通过采样计算.
通过采样计算.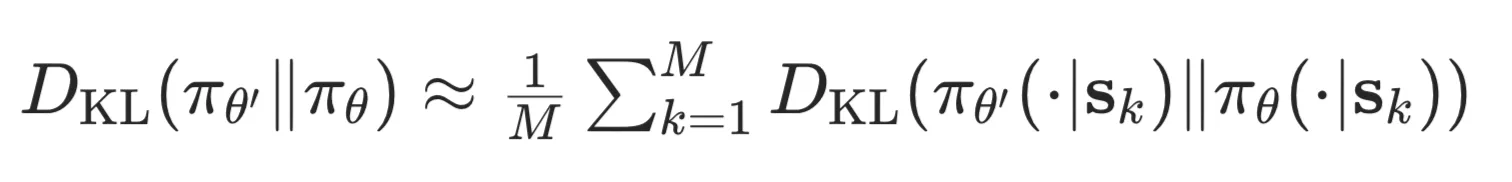
1# states: (B, S_dim) -> logits: (B, A_dim)2logits_old = policy_old(states)3logits_new = policy_new(states)4
5# 将 logits 转换为概率分布. 连续动作用 Normal 代替 Categorical6dist_old = torch.distributions.Categorical(logits=logits_old)7dist_new = torch.distributions.Categorical(logits=logits_new)8
9# 对所有样本取平均,得到最终的 KL 散度值10kl_divergence = torch.distributions.kl.kl_divergence(dist_new, dist_old).mean()- 进一步:通过 Fisher 信息矩阵近似展开 KL 散度:
- 可以通过采样来估计 .
- WHY this formula? see: [ai]
- 上图两种训练方法。选择 : natural gradient. 选择 : trust region policy optimization
- Lec5 end!



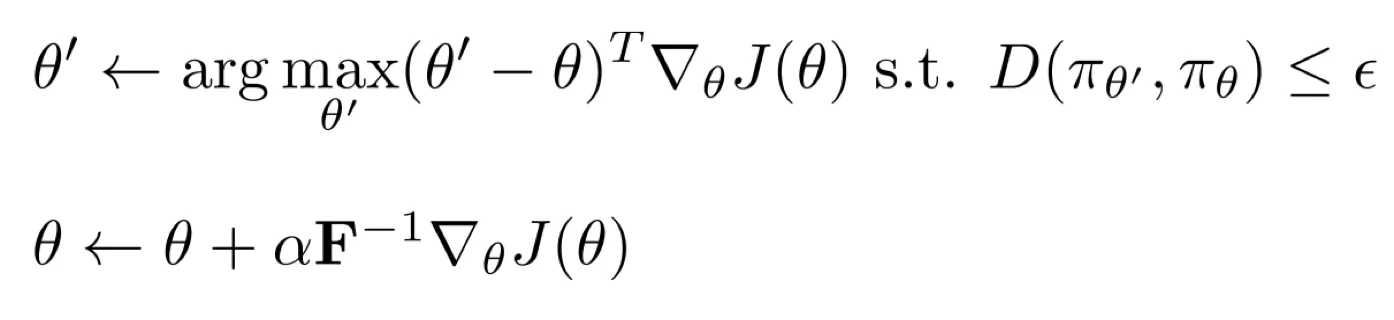
附录:PG 的 AI 简洁讲解
1目标是最大化:2
3J(θ) = 𝔼_{τ∼πθ}[R(τ)]4
5其中轨迹 τ 的概率依赖策略:6
7P(τ; θ) = ρ(s₀) ∏ₜ πθ(aₜ | sₜ) P(sₜ₊₁ | sₜ, aₜ)8
9环境转移 P 不依赖 θ,只有策略 πθ(a | s) 依赖 θ。10
11关键推导是 score function trick:12
13∇θ J(θ)14= ∇θ 𝔼_{τ∼πθ}[R(τ)] --> 这里没有梯度15= ∇θ ∫ P(τ; θ) R(τ) dτ --> 这里并不能用 ∑ P * R 来估计,别搞错了.19 collapsed lines
16= ∫ ∇θ P(τ; θ) R(τ) dτ --> 然后套入 $dif p = p dif log p$:17= ∫ P(τ; θ) ∇θ log P(τ; θ) R(τ) dτ --> 仔细看这里在 ∇ 左边引入了 P(τ; θ) 系数,从而可以提取出 𝔼18= 𝔼_{τ∼πθ}[∇θ log P(τ; θ) R(τ)]19
20而:21
22log P(τ; θ)23= log ρ(s₀) + ∑ₜ log πθ(aₜ | sₜ) + ∑ₜ log P(sₜ₊₁ | sₜ, aₜ)24
25只有中间那项依赖 θ,所以:26
27∇θ log P(τ; θ)28= ∑ₜ ∇θ log πθ(aₜ | sₜ)29
30因此 policy gradient 是:31
32∇θ J(θ) = 𝔼[∑ₜ ∇θ log πθ(aₜ | sₜ) Rₜ]33
34注意这个表达式的目的不是求 J(θ) 的梯度本身,而是求 J(θ) 的一个代理目标,等式右边是保留 ∇θ 符号的.