Behavior Prompting Policy: Demonstrations as Prompts for Manipulation (35)
⭐️⭐️⭐️ 将单条演示作为 in-context 任务提示 | 👤 Stanford, Austin Patel, Shuran Song | 🌐 | 📃 2606.30457 | ✨ | 📂 |
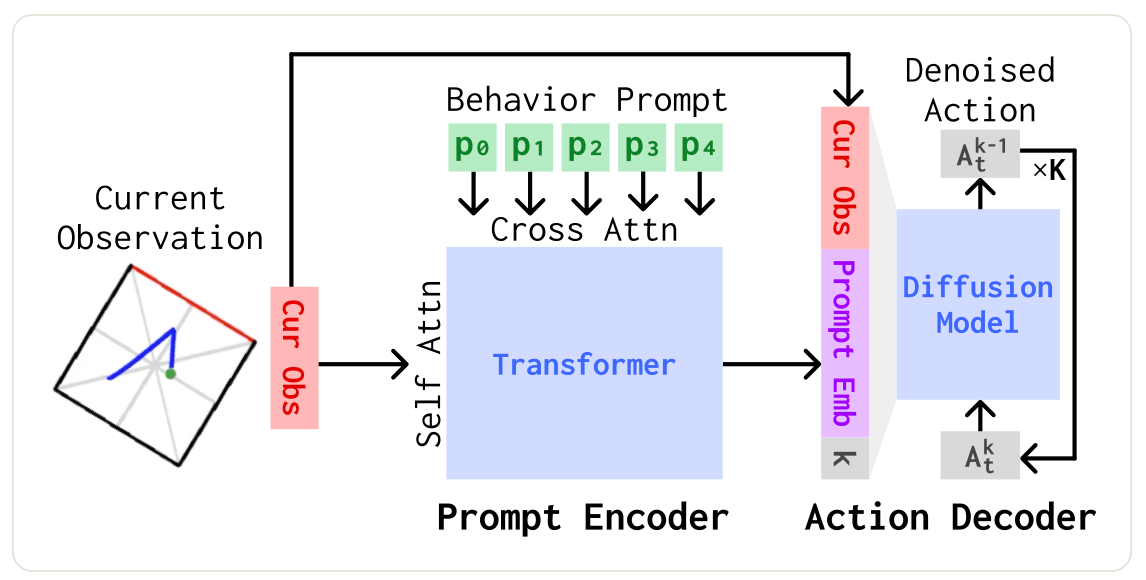
Recap: 众所周知,diffusion policy 使用 obs_encoder(obs) 获得 global_cond 并直接 FiLM 调制 UNet 中的多层 x.
本文仅需在上述 obs_encoder 内部 cross-attn 一条演示下采样得到的 [enc(rgb), mlp(propio), mlp(action)],实现了 1. infer-time 指定折叠方式(训练时见过多种折叠方式); 2. infer-time 指定绘制数字(训练时未见过的数字)。实验发现需要训练数据多样性高时才能很好地 steering,当然,还是无法跨 action primitive 的.
这篇文章 abs:
- We study Bahavior Propmting.
- To enable this, we present contributions in algo, data and evaluation.
- For algo, we.. For data we identify that .. is the primer driver and introduce iPhUMI.
SOE: Sample-Efficient Robot Policy Self-Improvement via On-Manifold Exploration (36)
⭐️⭐️⭐️ 在更低维度的 observation latent 上随机扰动来让 Policy 探索 | 👤 上海交通大学, Yang Jin, Chuan Wen、Cewu Lu | 🌐 | 📃 2509.19292 | ✨ | - |
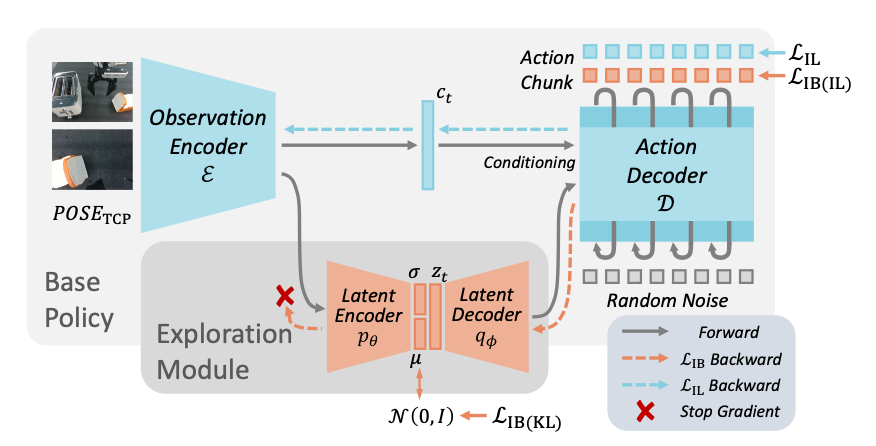
将 DP 的 observation z 压缩到更低维度的 latent 训练编解码[1],随后 infer 时对实际 observation z 编码 -> 扰动 -> 解码来生成新的且符合 on-manifold z,从而让 action 能安全高效地 RFT 探索[2].
- latent 编解码的训练目标为
max_θ I(A; Z) - β I(Z; O)(互信息在代码中通过 KL 散度实现). - RFT 探索很简单,就是生成多条候选轨迹,通过执行结果或人工筛选保留加入数据集,本质上是纯 IL.
FTP-1: A Generalist Foundation Tactile Policy Across Tactile Sensors for Contact-Rich Manipulation (37)
⭐️⭐️⭐️⭐️ 将独立 tactile expert 加入 MoT 并提出一种异构触觉 sensor 的统一编码 | 👤 Tsinghua University, Chengbo Yuan, Yang Gao | 🌐 | 📃 2606.13102 | ✨ | 📂 |
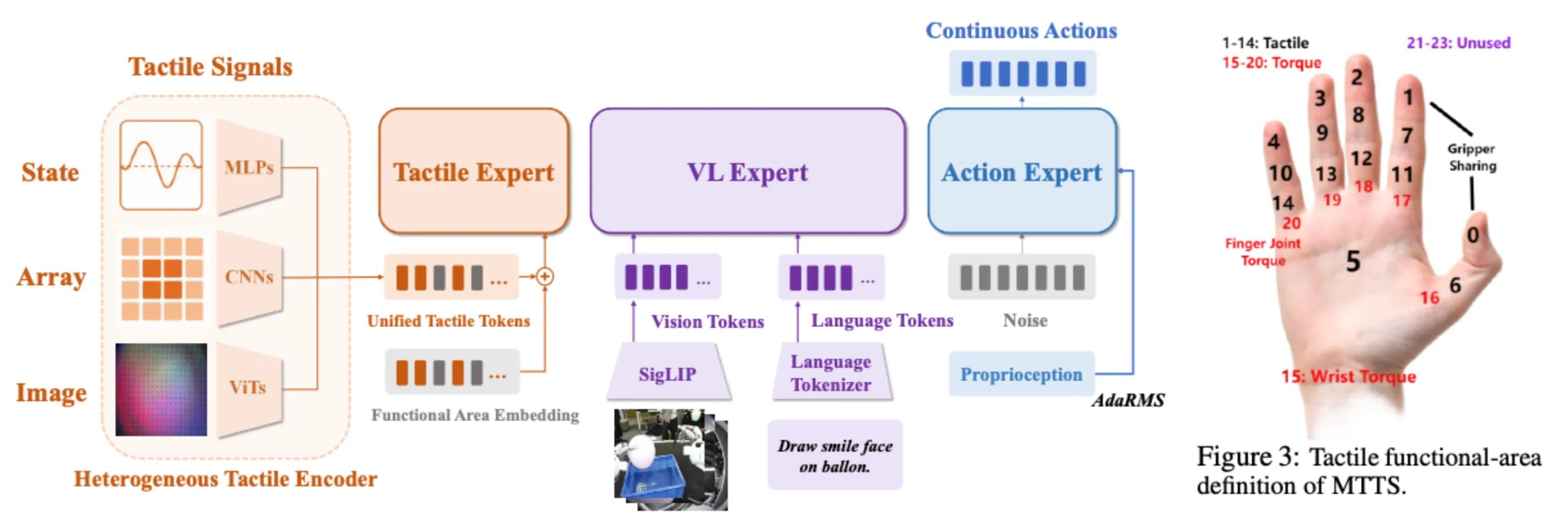
将各种 tactile sensor 统一投影并输入从零训练的 300M transformer,MoT 中仅需让 action expert 去 attend tactile expert. 依旧使用异构预训练 + 特定任务微调,都仅冻结 siglip.
一些有趣结论 1) 实验发现,pi0.5 比一些基础 tactile 模型表现更优,怀疑是 tactile 信号损害了 action 和 VLM. 2) FTP 动作比 baseline 更平滑. 3) 据说跨传感器时涌现了减速 (slows down the insertion motion based on tactile feedback).
附:统一投影方式
图像型 (如 GelSight)
- Tactile Image -> [Sensor-specific ViT] -> feature maps -> [Shared T3 Transformer] -> CLS token -> [LayerNorm] -> [MLP] -> Tactile Token
阵列型 (如 Contactile)
- Tactile Array -> [Fourier Encoding] -> expanded signal -> [3-layer CNN] -> spatial features -> [MLP] -> [LayerNorm] -> [MLP] -> Tactile Token
状态型 (如 力/力矩)
- Tactile State -> [Fourier Encoding] -> expanded signal -> [3-layer MLP] -> [LayerNorm] -> [MLP] -> Tactile Token
然后 + embedding
- Tactile Tokens -> [+ Shared Functional Area Embedding] -> MTTS Tokens -> [Tactile Expert]
VGGT: Visual Geometry Grounded Transformer (38)
⭐️⭐️⭐️⭐️⭐️ 简单有效的3D重建方式 | 👤 牛津大学&Meta, Jianyuan Wang, David Novotny | 🌐 | 📃2503.11651 |✨ |📂 |
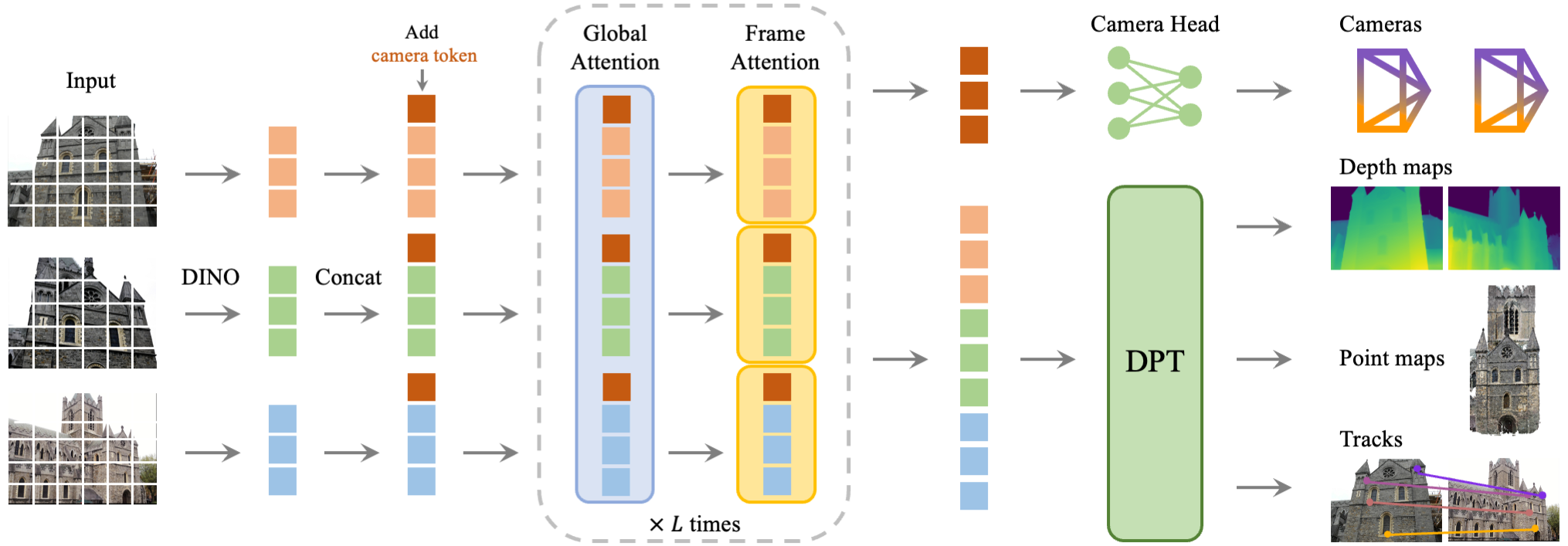
对N张图或1张图提取 DINO feature 每图 (b, len, dim), concat 所有图 feature (b, len*N, dim),然后交叉进行单图 attn 和所有图 attn. 然后接输出头直接预测相机参数、深度、点图和追踪. 主要用开源数据集,由于12亿参数+监督强劲,效果非常好.
Learning Versatile Humanoid Manipulation with Touch Dreaming (39)
⭐️⭐️⭐ 将手部触觉和力作为 aux tasks 的全身操作. | 👤 卡内基梅隆大学, Yaru Niu, Ding Zhao | 🌐 | 📃 2604.13015 | ✨ | 📂 |
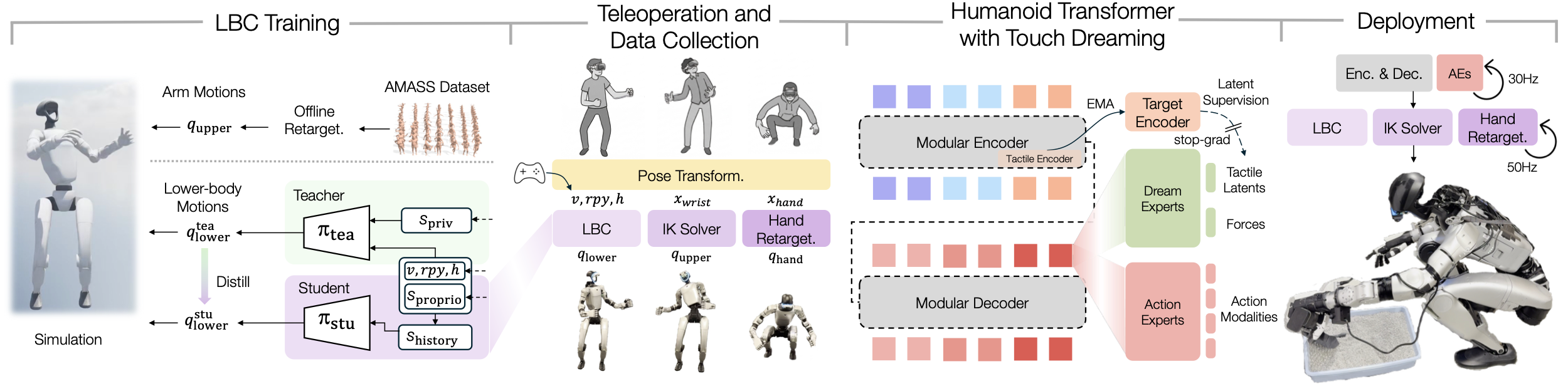
使用 ACT 变体输出全身动作,其中下半身交由独立 RL 控制器. 手用的是 Inspire tactile hand.
STEAM: Self-Supervised Temporal Ensemble Advantage Modeling for Real-World Robot Learning (40)
⭐️⭐️⭐ 将帧时间差作为 frame-level advantage | 👤 中科院自动化所, Zhihao Liu, Xinlei Chen、Chao Yu | - | 📃 2606.29834 | ✨ | - |
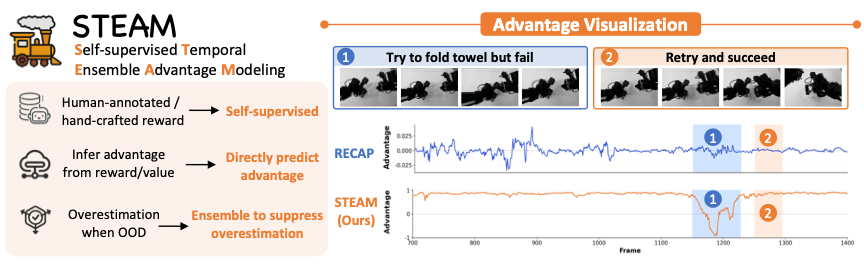
直接把所有视频时间戳归一化到 0~1 并离散化,先训 predictor[1],然后对于每一帧减去 baseline 计算优势 [2],以 q 分位数为阈值给每帧打二元标,作为 CFGRL[3] 输入的 condition.
方法利用成功轨迹的倒放来提供回归动作的负样本,并用悲观估计抑制分布外数据优势分数被高估的问题。但文章没有做 predict continuous offset 和 bin offset 的 ablation,也没有考虑长程任务 (frame_i, frame_j) 是否足以推断进度信息以及专家轨迹进度不均衡问题. 文章有点 AI.
(frame_i, frame_j, l) -> offset_prob (CrossEntropy GT_offset_onehot)- 固定 H,
predictor(i, i + H).expected_index() - H / episode_len - training-time action diffusion 过程中
predicted_noise = model(noisy_action, state, condition, t),其中 condition 以 20% 概率丢弃为 null_token 以训练无条件分布. inference-time diffusion 过程中eps_uncond = model(action, state, null_token, t), eps_cond = model(action, state, target_condition, t), eps_guided = 加权,不用 autograd.
AHA-WAM Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing (41)
⭐️⭐️⭐⭐ 用最新观测修正长期 video plan 从而实现 v-a 异步 | 👤 Shanghai Jiao Tong University, Jisong Cai, Yao Mu | 🌐 | 📃 2606.09811 | ✨ | 📂 |
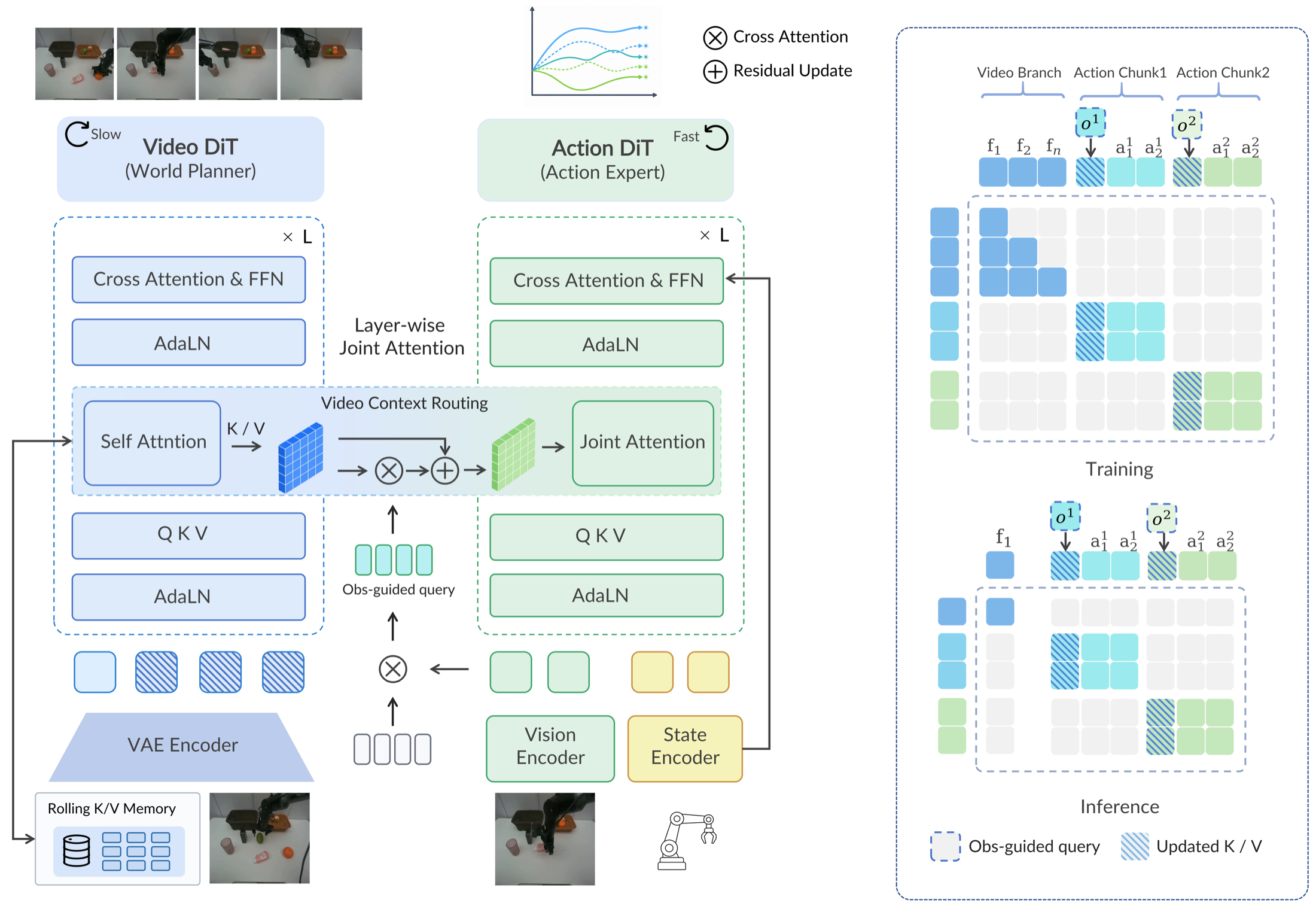
本文希望每次 video denoise 后可以进行随机多次 action denoise. 本文基于 fastwam,首先添加了 6 帧 video 历史,然后每次 action denoise 时,使用了类似 ACT 中 DETR 的槽位查询: 为了让 current image 修正 kv histroy,先学习 learnable query emb,通过 cross attn image,然后再 cross attn layerkv,再 mlp,而且使用了 delta.
于是 video dit 和 action dit 可以异步或并发运行,video dit 可以在任意时刻更新历史 kv,并且 action dit 不需要等待它. 一些有趣技巧 1) 训练时随机平移 action 对应的 history kv index 以适应并发推理. 2) Cuda 加速单独提速 10 倍. Action dit ODE 蒸馏 (teacher-student) 10 步降到 2 步. 注意到 cuda 提速之前比 fastwam 慢,毕竟 action dit 要做的事情一样还有额外历史查询.
对于解决 WAM 恐怖的 video dit 延迟来说,异步是一个不错的思路(而 slots 是一种实现方式),部署也会更为简单. 这种思路似乎可以直接迁移到 IDM,只不过需要验证该范式是否有效. 本文 Demo 只有双臂 picknplace.
1current_image # [B, 3, H, W] 新观测.2history_video_k, history_video_v # 历史信息, 每 layer 都是 [B, L_v, D]3query_emb # [Q, D_q] 学习的.4
5obs = image_encoder(current_image) # [B, N_img, D_img]6guided_query_emb = cross_attn(query_emb -> obs) # [B, Q, D_q]. Attention pooling.7for (layer_k, layer_v), mlp_this_layer in zip(history, mlps):8 residual = cross_attn(guided_query_emb -> layer_k layer_v) # 获取视觉差9 delta_k, delta_v = mlp_this_layer(concat(guided_query_emb, residual)) # 获取 kv 差10 updated_kv.append((layer_k + delta_k * alpha, layer_v + delta_v * alpha))11# MoT: action_dit 每一层对应一个 updated_kv.12action_v = action_dit(noisy_action, updated_kv, state_emb)RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies (42)
⭐️⭐️⭐ 26年7月非常难的 benchmark | 👤 MMLab@HKU, Tianxing Chen, Ping Luo | 🌐 | 📃 2607.04434 | ✨ | 📂 |

pi0.5 果然是最强的. 仿真改用 issac lab 并给出难点方向 1) 泛化 e.g. 光照; 2) 记忆 e.g. 交换同色块; 3) 准度 e.g. 插小试管; 4) 长程 e.g. 下圈叉棋; 5) 开放 e.g. 算术题. 真机用 PiperX 等机械臂,也有合笔盖等 high precision 任务. 最强的 拿了 12% 左右分数. 仿真数据用 curobo 和遥操,真机数据遥操(每个任务 100 条).
本文实验发现当前 VLA 在如下方面有严重问题:场景泛化; 长程任务; 错误恢复; 用记忆指导动作; 开放问题.
---
AHA-WAM: Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
[Gemini 3.1 Pro,AI 补充] AHA-WAM 将世界动作模型拆分为低频长时 Video DiT 和高频动作 Action DiT,二者通过观测引导的上下文路由异步协同。 | 👤 上海交通大学, Jisong Cai, Yao Mu | 🌐 | 📃 2606.09811 | ✨ | 📂 |
方法包含两个解耦的扩散 Transformer,低频 Video DiT 充当维护历史观测 KV memory 的规划器,高频 Action DiT 通过层级交叉注意力查询规划器特征以预测 action chunk。为了让旧特征适配新观测,模型通过最新视觉观测生成 routing queries 对缓存特征进行注意力池化,从而在不重跑视频 DiT 的情况下实现高频动作闭环。 作者还利用 ODE 蒸馏将 Action DiT 降噪压缩至两步推出了 Flash 版本,文章坦言局限性在于两者的运行频率以及预测步长等时间超参数均需要根 据任务手动调节。
Motus: A Unified Latent Action World Model
[Gemini 3.1 Pro,常见 baseline] 引入 Mixture-of-Transformer 架构集成三大专家,并用光流提取隐式动作进行大规模预训练 | 👤 清华大学, Hongzhe Bi, Jun Zhu | 🌐 | 📃 2512.13030 | ✨ | 📂 |
Motus 采用 Mixture-of-Transformer 架构集成理解、视频生成和动作三个专家,并使用 UniDiffuser 风格的调度器灵活切换世界模型和 VLA 等模式。为了利用大规模异构数据,文章通过光流提取像素级隐式动作,并设计了包含基础模型、隐式动作联合预训练和目标机器人微调的三阶段训练流程。 文章证明了将视频生成和动作预测统一在一个模型中,能显著提升下游真实机器人任务的表现。
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
[Gemini 3.1 Pro, FTP 使用] UniDex 将人类视频重定向为机器人轨迹并提出统一动作空间 FAAS,训练出支持多种灵巧手的 3D VLA 模型。被 FTP 使用. | 👤 清华大学, Gu Zhang, Huazhe Xu | 🌐 | 📃 2603.22264 | ✨ | 📂 |
UniDex 首先通过带人工微调的逆运动学将人类视频重定向为机器人轨迹,接着提出按功 能对齐关节的统一动作空间 FAAS,最后使用 Uni3D 编码单视角点云并结合 FAAS 动作空间,通过流匹配目标训练出支持多种灵巧手的 VLA 模型。
当前方法没有利用无动作标签的大规模第一人称视频,且重定向过程仍需要一定的人工 干预。
T3: Transferable Tactile Transformers for Representation Learning Across Diverse Sensors and Tasks
[Gemini 3.1 Pro,FTP 用它编码触觉] T3 提出了一个共享主干结合特定传感器编码器和特定任务解码器的框架,用于跨多种异构触觉传感器的表示学习。 | 👤 MIT CSAIL, Jialiang Zhao, Jialiang Zhao | 🌐 | 📃 2406.13640 | ✨ | 📂 |
T3 首先聚合了包含 13 种传感器和 11 个任务的大规模触觉数据集 FoTa,接着使用掩 码自编码器进行自监督预训练,最后利用部分有标签数据进行监督学习微调。 当前 FoTa 数据集存在数据不平衡问题,模型侧重于单图编码,且仅限于基于相机的触觉传感器。
YUBI: Yielding Universal Bidigital Interface for Bimanual Dexterous Manipulation at Scale
[Gemini 3.1 Pro,类似 RoboPocket] YUBI 设计了贴合手指的轻量化夹爪结合 Quest 追踪,采集了超大规模双臂数据集并训练了跨本体部署策略。 | 👤 AIRoA, Takehiko Ohkawa, Kei Ota | 🌐 | 📃 2606.10244 | ✨ | 📂 |
YUBI 设计了一种贴合人类手指运动的轻量化数据采集夹爪,它使用 Quest 3S 提供 6DoF 追踪,相比 UMI 收集了超过 8000 小时的大规模双臂数据集,并基于这些数据训练了基于 π0.5 的多任务策略,只需给不同机械臂安装 YUBI 夹爪就能直接实现跨本体部署。
GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
[Gemini 3.1 Pro,看起来房间重建效果好] GenRecon 将 3D 生成先验引入多视角重建,通过分块生成并解码为带有 PBR 材质的完整室内场景网格。 | 👤 Technical University of Munich, Katharina Schmid, Matthias Nießner | 🌐 | 📃 2605.23888 | ✨ | 📂 |
GenRecon 将输入视角特征投影到统一的 3D 体素网格中,解决标准 3D 生成模型缺乏相机位姿控制的问题。它将场景划分为重叠的三维块并在共享潜在空间中联合生成,可以利用如 Trellis.2 这样的对象级强先验来补全未观察到的区域,重建出支持重新打光的高保真完整场景。
TacVLA: Contact-Aware Tactile Fusion for Robust Vision-Language-Action Manipulation
[Gemini 3.1 Pro,经典触觉] 引入接触感知门控机制,仅在接触时激活触觉 Token 以避免干扰 | 👤 普渡 Purdue University, Kaidi Zhang, Yu She | 🌐 | 📃 2603.12665 | ✨ | 📂 |
TacVLA 通过接触感知门控机制选择性激活触觉 Token,并将其与视觉和语言在 Transformer 中联合处理。这避免了无关触觉干扰,增强了跨模态对齐,显著提升了视觉遮挡和富接触环境下的细粒度操作成功率。
Tactile-VLA: Unlocking Vision-Language-Action Model’s Physical Knowledge for Tactile Generalization
[Gemini 3.1 Pro, 经典触觉] 结合混合位置力控制器与推理模块,激活 VLM 先验物理知识实现触觉零样本泛化 | 👤 Tsinghua University, Jialei Huang, Yang Gao | 🌐 | 📃 2507.09160 | ✨ | 📂 |
Tactile-VLA 深度融合了视觉、语言、动作和触觉,并利用混合位置力控制器将意图转化为物理动作。它通过推理模块根据触觉反馈调整策略,只需少量演示就能激活 VLM 已有的物理交互语义,从而在富接触任务中实现触觉泛化。
ForceBand: Learning Forceful Manipulation with sEMG
[Gemini 3.1 Pro 腕带记录力] 提出一种结合肌电图和惯性传感器的手腕手环,通过收集多模态数据训练出能够预测细粒度指尖受力的模型 | 👤 Amazon FAR, Botao He, Ruoshi Liu、Haozhi Qi、Yiannis Aloimonos | 🌐 | 📃 2606.26093 | ✨ | - |
收集包含第一人称视频、肌电图、惯性传感器和真实指尖受力的多模态数据集,预训练一个提取时频特征的模型来预测手指受力,在特定用户简短校准后即可仅靠手环和视频收集带有受力标签的演示数据,最后通过流匹配策略网络同时预测机器人动作和力。
实验表明按照人体肌肉解剖学位置分布的电极比均匀分布能更准确地预测受力,同时这种不需要在指尖安装传感器的方案也避免了对视觉信息的遮挡。