ALOE (9): 智元 Rushuai Yang | Maoqing Yao
一句话:bc 预热后在 rollout 过程中训练一个 Q_net(critic) 支持干预,并从replay-buffer(原始数据、人类干预和历史rollout轨迹)中采样一个带奖励的转移 (s, a_chunk, r_chunk, s_next),自举部分则使用 Q_net(current_policy(s_next)),估计悲观奖励 Q_pess 的同时更新 Q_net,随后 Q_net 评估 current_policy 在 s 处的多次采样平均表现. 如果 a_chunk 价值比 s 高则给 a_chunk 整个高权重. demo 装手机还不错.
- 实际上使用多个 Q_net 取 min 来进行悲观估计.
- Q_net 这部分看出是 off-policy 的,因为这里
r来自 replay_buffer 而a_next = current_policy(s_next)则来自 current_policy. 这是 off-policy 多种形式中的一种.
GreenVLA (10)
有很多训练 trick,包括5阶段课程学习、质量指标筛选(公开数据集质量表). 然而,demo 没有什么新东西。
GuidedVLA: ybw (11)
一句话:给 pi0 action expert 加深度、action-primitive 和 attn mask 的 auxiliary tasks 和特征
这三个特征均可用外部 VLM, depthanything 和 SAM 打标签.
- 在 mot 的 action expert 的 [9, 10, 11, 12] 层 block 中,让 action tokens 的 q 去 attend
depth_proj(depth_enc(img))的 kv 得到 y1,由 depth anything 监督. - 新的一条路径:
action tokens -> q; concat(image tokens, action tokens) -> kv用于:- 计算 这里 qk 的 attn score,这个 score 和 GT attn mask patchified 得到 obj_loss (GT 由其他 grounding 模型生成)
- 以及产生 pred_skill(one-hot,类似于 “pick” “place” “hold” 分类),计算额外 skill_loss. 除了 loss 还会得到 y2 y3.
- action tokens += linear(concat(y1, y2, y3))
- 上述 qkv 在代码中被称为 control_qkv [1]. y1 y2 y3 带门控.
- 关于 control net:
1output = original_attention(x) + # 这里是 pi0 原始的.2 linear(control_attention(x)) # 只不过这里 linear 初始化为 0 防止初始就让老模型乱掉Interleave-VLA: fcx (12)
1 # 输入包含当前观测图像、交错的图文指令及机器人状态2 # 使用 <BOI>/<EOI> 特殊 Token 标识指令中的参考图像3-instr_tokens = tokenizer.encode("把那个蓝色的带条纹的勺子放到盘子里") # 常规 VLA4+instr_tokens = tokenizer.encode(f"把 <BOI>{crop_img}<EOI> 放到盘子里") # 本方法,操作者在GUI手动框选目标5 obs_tokens = visual_encoder(current_observation)6 # 将观测、交错指令和本体感受状态拼接为统一序列7 input_seq = concat(obs_tokens, instr_tokens, robot_state)8 # VLA 模型直接生成连续动作序列9 actions = VLA_Model.predict(input_seq)flowchart TD
img["Observation Images
(B, n_cam=3, H=224, W=224, C=3)"] --> siglip["PaliGemma Image Encoder(SigLIP)"]
instr_img["Instruction Images (Crops/Web/Sketch)
(B, n_imgs, 224, 224, 3)"]:::highlight --> siglip
txt["Interleaved Tokens (Text + BOI/EOI)
(B, max_len=N)"]:::highlight --> tok["Gemma Tokenizer + Special Tokens"]:::highlight
siglip --> obs_vis["Observation Tokens
(B, 3*256=768, D=2048)"]
siglip --> instr_vis["Instruction Visual Tokens
(B, n*256, D=2048)"]:::highlight
tok --> textemb["Text Embeddings
(B, N, D=2048)"]
instr_vis --> inter_instr["Interleaved Instruction Embeddings
(Text Tokens & Visual Tokens Mix)"]:::highlight
textemb --> inter_instr
obs_vis --> prefix["Prefix Tokens (Obs + Interleaved Instr)
(B, seq_len, D=2048)"]:::highlight
inter_instr --> prefix
state["Robot State
(B, action_dim=32)"] --> stateproj["state_proj"]
noisy["Noisy Actions x_t
(B, horizon=50, action_dim=32)"] --> actproj["action_in_proj"]
time["Flow Time t
(B,)"] --> timemlp["Time Embedding MLP"]
stateproj --> statetok["State Token
(B, 1, D=1024)"]
actproj --> acttok["Action Tokens
(B, 50, D=1024)"]
timemlp --> timetok["Time Tokens
(B, 50, D=1024)"]
acttok --> mix["Action + Time Tokens
(B, 50, D=1024)"]
timetok --> mix
statetok --> suffix["Suffix Tokens
(B, seq_len=51, D=1024)"]
mix --> suffix
prefix --> pg["PaliGemma / Gemma 2B Expert"]
suffix --> ae["Action Expert / Gemma 300M"]
pg <--> shared["Shared Masked Self-Attn (qkv dim=256)"]
ae <--> shared
shared --> actout["action_out_proj"]
actout --> vt["Predicted v_t
(B, 50, action_dim=32)"]
gt["Target u_t = noise - action
(B, 50, action_dim=32)"] --> loss["Flow Matching Loss"]
vt --> loss
classDef highlight fill:#ffff00,stroke:#333,stroke-width:2px;
Implicit RDP (13)
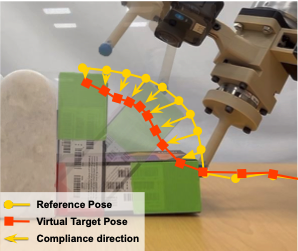
一句话:在一个 img 周期内构建高频的短期 wrench kv memory 并在 train-time-only 加入 virtual_target 和 stiffness auxiliary tasks 来强制模型利用力信息,推理时仅需力传感器+位控且并且没有用 admittance control. 例如在插入书本等任务中,如果书本怼到墙壁能快速感知到并反应.
力 reactive + 位控比较适合上述书本插缝的情形,但并不适合套手机壳;后者更需要力控,但力控对于到达目标点的反应却更慢。两者之间存在 tradeoff. 从一个角度考虑, 人手没有编码器实际上不能做位控,机械臂擅长做位控任务,但前者却能实现一系列灵巧操作,到底是怎么控制的?
1noisy_action[i] ---attend--> noise_action[<=i] & fast_kv[<=i] & slow_kv2fast_kv[i] 内部为 GRU,slow_kv 内部为 obs_encoder1# Train: 不用随机采样 fast kv length2# batch aligned around slow time S, with dense force covering slow history -> action horizon3slow_obs = {4 img: img_slow[:, S-1:S+1], # (B,2,3,360,640), slow history5 tcp_pose: tcp_slow[:, S-1:S+1], # (B,2,6)6}7fast_obs = wrench_fast[:, F0:F0+16] # (B,16,6),8a0 = action_aug[:, F0:F0+16] # (B,16,13), aug 的意思就是 6 tcp + 6 virtual target + 1 stiffness9slow_kv = SlowEncoder(slow_obs) # (B,~100,768), slow cross-attn K/V10fast_kv = FastGRU(fast_obs) # (B,16,768), causal fast K/V11eps = randn_like(a0); k = randint(0,K,(B,))12xk = add_noise(a0, eps, k) # (B,16,13), noisy action tokens / Q source13pred = Transformer(xk, k, slow_kv, fast_kv) # (B,16,13), causal: action i sees fast_obs <= i14target = eps # or v_target under v-prediction15loss = mean((pred - target) ** 2) # diffusion loss over B x 16 x 13实际上不论是采数据还是 infer-time,原始数据的 img, tcp_pose 和 wrench 都是同步同频率 (e.g 10hz),只是 img, tcp_pose 大部分被忽略了.
1# Infer: slow #1: step_count % tcp_action_update_interval == 0, default update_interval=62obs = env.get_obs(obs_steps=2) # 同频同步帧: img/tcp_pose/wrench, each length=23slow_kv_1 = SlowEncoder(obs) # conceptually (B,102,768)4noise_1 = randn(B,16,13) # cached noisy trajectory for this chunk5# infer #1, step_count % 6 == 06N = latency_step + 0 + n_obs_steps # default 2 + 0 + 2 = 47ext_obs = env.get_obs(obs_steps=N) # recent N synchronized wrench frames8fast_kv = FastGRU(ext_obs["right_robot_tcp_wrench"]) # (B,4,768)9x = DDIM(noise_1[:, :N], slow_kv_1, fast_kv) # (B,4,13)10execute(x[:, -1, :6]) # only tcp pose; vt/stiff discarded11# infer #2, same slow_kv/noise, step_count % 6 == 112N = latency_step + 1 + n_obs_steps # 513ext_obs = append_one_new_obs_and_keep_last_N(ext_obs) # recent 5 synchronized wrench frames14fast_kv = FastGRU(ext_obs["right_robot_tcp_wrench"]) # (B,5,768)15x = DDIM(noise_1[:, :N], slow_kv_1, fast_kv) # (B,5,13)12 collapsed lines
16execute(x[:, -1, :6])17# infer #3 ...18N = latency_step + 2 + n_obs_steps # 619fast_kv = FastGRU(recent_sync_wrench[:N]) # (B,6,768)20x = DDIM(noise_1[:, :N], slow_kv_1, fast_kv)21execute(x[:, -1, :6])22# ...23# next slow update when step_count % 6 == 0 again24
25obs = env.get_obs(obs_steps=2)26slow_kv_2 = SlowEncoder(obs)27noise_2 = randn(B,16,13)Adaptive Compliance Policy (14)
预测 virtual target 和 stiffness 从而在纯位控机器人上使用 admittance control
VP-VLA: Zixuan wang 港科大 (15)
全程冻结 VLM 和 SAM 并直接在 pixel level 绘制锚点. 并且让 VLA 中的 VLM 对齐外部的 VLM.
Do World Action Models Generalize Better than VLAs? A Robustness Study (16)
⭐️⭐️⭐️ 在仿真中评测并认为 WAM 比 VLA 的鲁棒性和泛化更强. [Huawei Technologies, Zhanguang Zhang, Zhanguang Zhang 和 Yingxue Zhang]
| https://hjfy.top/arxiv/2603.22078 | https://www.alphaxiv.org/abs/2603.22078 |
|---|
本文在 LIBERO-Plus 和 RoboTwin 2.0-Plus 基准上评测了多款 VLA 和 WAM,发现 WAM 对视觉和语言扰动展现出更强的鲁棒性,训练数据更简单,而 VLA 通常需要海量多样化数据才能达到类似效果。但 WAM 的高延迟限制了其在真实系统中的部署。
BORA: czx (17)
本文在离线训练 Q net, V net(仅用于辅助训练 Q_net) 的同时更新 vlm encoder,并在在线阶段冻结 Q,只额外训练一个 MLP 级别的 residual policy.
demo 仅限慢速 pick and place 以及食指大拇指的简单捏握.
Offline RL
flowchart TD
obs --> vlm[[vlm]] --> z
z --> value_net[[value_net]] --> V["V[] 数组"] --> v_loss["loss_v =
expectile_loss(Q.detach(), V)"]
z --> policy[[consistent_policy]] --> A["A[] 数组"] --> Q[[Q_net]] --> q_loss["loss_q =
bellman_residual(Q, reward, V_next)
这里 V_next = V_net(GT z_(t+1))"]
policy --> v[[1~3次去噪]] -->policy
A --> loss_act["loss_act =
-ppo_clip(A, advantage(Q, V))
+ λ_bc * bc_loss(A, A_demo)"]
- expectile_loss: [todo]
1diff = Q.detach() - V2weight = torch.where(diff > 0, tau, 1 - tau)3loss_v = torch.mean(weight * (diff**2))
- bellman_residual:
1y_t = reward + gamma * (1 - done) * V_next2loss_q = torch.mean((Q - y_t.detach())**2)
Online RL
flowchart TD
obs --> vlm[[🧊vlm]] --> z
z --> policy[[🧊consistent_policy]] --> A_base --> Q1[[🧊Q_net]] --> Q_base --> target
z --> residual[[🔥residual_policy]] --> A_res --> A_final["A = A_base + λ A_res"] --> Q2[["🧊Q_net (同一个)"]] --> Q_final --> target
policy --> v[[1~3次去噪]] -->policy
A_base --> A_final
target["target =
hinge(Q_base + δ - Q_final) - Q_final
ps: hinge is max(0, x)"]
递归
- Q-chunking 就是本文使用的给 action_chunk 的每个位置打分.
- implicit Q learning 就是:
- 非 implicit 更新 Q_net:
target = reward + gamma * max(Q_target(s_next, policy(s_next))). 如果 policy 输出 OOD 的动作,Q 的评分可能虚高,policy 被诱导去选择这些幻觉动作,导致整个评价体系崩溃. - implicit 更新 Q_net:
1diff = Q.detach() - V2weight = where(diff > 0, τ, 1 - τ) # 当 Q > V 时权重为 τ=0.7,当 Q < V 时权重为 1-τ3# 实际这里还需要 * (1 - dones)4loss_V = mean(weight * (diff**2))5target = reward + gamma * V(s_next)
- 本文没有直接使用 IQL 而是使用了 IQL-style expectile.
- 非 implicit 更新 Q_net:
一些概念
- stiffness: F = K * (x_des - x) + D * (v_des - v),这里的 stiffness 就是 K. K 越大,同样的位置误差会产生越大的修正力/力矩.
- 力位混合控制:选择一些轴力控,一些轴位控. 如 X, Y 走位,Z 保持 10N 下压力. 力控目标通常是末端[Fx, Fy, Fz, Mx, My, Mz] 扭矩(例如 Mz 可以理解为绕 z 轴转,拧螺丝),控制器内部通过雅可比矩阵
tau = J^T * wrench转换为各关节扭矩.
Latent Policy Barrier (18) LPB
一句话: 在 diffusion 过程中对 action 加入 guidance 项使得下一时刻的潜在观测与最近专家潜在观测的距离尽量小.
具体而言,下一时刻的潜在观测是通过训练的动力学模型 d(z_t, a_(t, chunk)) -> z_(t + tp) 得到的,该模型的训练数据来自专家轨迹 + 早期 ckpt 的 rollout 轨迹,在 infer-time 冻结。而 guidance 要求 d 的参与,而前几个去噪步让 d 难以预测,因此文章在 100 步去噪的最后 10 步才执行 guidance.
cosmos-policy (19)
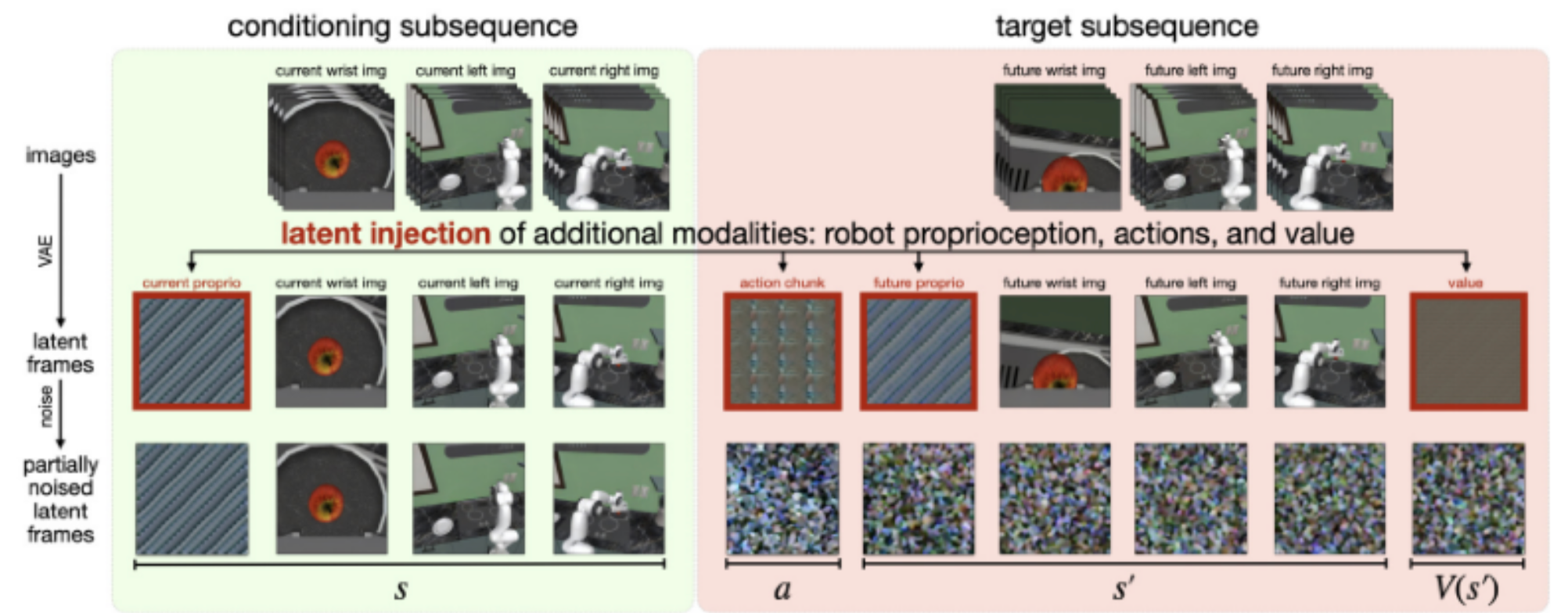
一句话:使用 video model 直接预测 proprio token, action token 和 value token.
这三者是 minmax 然后直接被广播到 CxHxW 的 image token 形状, 还支持预测 V(s) 从而实现从 rollout 数据中学习以及 model-based planning (1 action -> 3 states -> 15 Q(s, a)). demo: picknplace, 叠衣服, 拉拉链. 注意下图中,设 action chunk len = K,状态 s 所在时间为 t,则 s’ 所在时间是 t + K (即这一整个 action chunk 执行完毕以后). 一个 action chunk (chunk_size, action_dim) 对应一个 latent frame. video backbone 使用的是 cosmos-predict2-2B.
Wall-WM: 自变量 (20)
wall-wm train-time 用 event-chunk 替代了 time-chunk,并且提出了一种 infer-time 分层加速解码方式,基模是 Wan2.1-1.3B。自变量这个文章写得非常长,解释了很多架构设计细节。然而,demo 只展示了泛化的 picknplace. 一些技巧包括:
- 几何约束: 多相机 attn mask 做了几何约束,并为每个相机学习一个 RoPE. 没有单独消融实验.
- state token: 每 transformer layer 都有从 action token 到 state token 的单独 crossattn,不会因为 pi 那样完全 self attn 稀释注意力到 video token. 没有消融实验.
- 变长解码:用 vlm 决定事件对应的 event-chunk 长度 n,然后对
(n + 1) * K_p(每个 video latent 解码 K_p 个 action token,当前观测帧也是一个 video latent) 个带位置编码的噪声去噪. 消融实验的 baseline 去掉了变长解码和几何约束,并发现本方法在平均任务进度得分上领先.
flowchart TD
cap(["事件描述 ℓ_i
(event 模式, 变长)"]) --> t5[["T5 文本编码"]]
instr(["全局指令 + 历史
(仅 unified 模式下)"]) --> qwen[["Qwen3.5-9B VLM 🧊"]]
qwen --> stair[["🟢创新: Staircase 解码器
中间层后并行一次性出
几个思考向量, 不逐字生成"]]
t5 --> cond(["文本条件 c_ℓ"])
stair --> cond
%% ---------- 视频塔 ----------
v0(["当前多视角观测 V0
(B, n_cam=3, H, W, 3)"]) --> vdit
cond --> vdit
vdit[["🟢创新: 多视角 Video DiT 🧊
跨相机注意力 + Camera RoPE
+ Sight-Cone 只看共视区域
(动作训练阶段冻结)"]]
vdit --> vfeat(["逐层视频特征 h^v"])
vdit --> vloss["视频 Flow-Matching Loss"]
%% ---------- 动作塔 ----------
state(["机器人状态 s"]) --> ea
nact(["噪声动作 a_t
(B, K_p·(1+n) 变长, act_dim)"]) --> ea[["MLP 编码 E_a"]]
ea --> adit[["动作 DiT (与视频塔同深度)"]]
cond --> adit
vfeat -. "🟢创新: 单向耦合
每层 q=动作 / k,v=视频特征" .-> adit
state -. "🟢创新: 每层专门 cross-attn 读状态
不被海量视频 token 淹没" .-> adit
adit --> vt(["预测 v_t
(B, K_p·(1+n), act_dim)"])
vt --> aloss["动作 Flow-Matching Loss"]