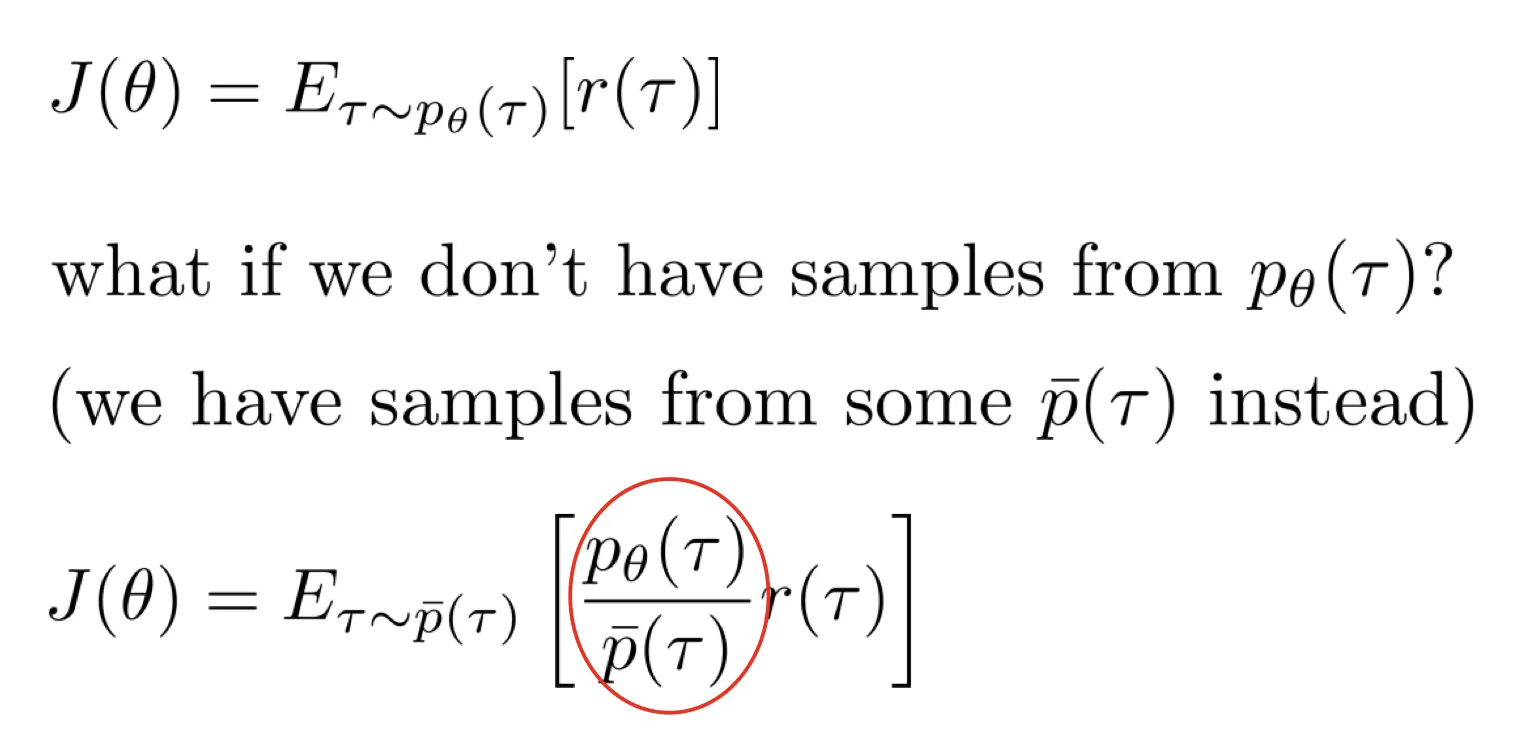https://rail.eecs.berkeley.edu/deeprlcourse-fa23/
- hw1: https://rail.eecs.berkeley.edu/deeprlcourse-fa23/deeprlcourse-fa23/static/homeworks/hw1.pdf
- hw2:
符号
-
: 策略的累积奖励的期望,需要最大化
-
顺序:
-
: 轨迹,表示所有
-
:状态 下采取 的概率
-
状态价值函数 state-value function,即还不确定
-
动作价值函数 action-value function,即确定了
- 有
- 有
强化学习类型
- Policy Gradient: 求 对 的导数.
- 训练:
- Actor: 输入
[机械臂状态,观测] - 输出
[动作]或者[动作的概率分布]
- Actor: 输入
- 推理: 一样
- 训练:
- Value Based (DQN): 直接训练一个 Q / V,取最大值对应的动作索引 (no explicit policy)
- Actor-Critic: 有 A 有 Q
- Model-based: 有模型自行估计 经过 如何转移 ( learn )
On-off policy
-
off-policy: able to improve the policy without generating new samples from that policy
-
on-policy: any time the policy is changed (even a little bit) we need to generate new samples.
-
(and there is offline-RL)
Lec5 Policy Gradients
- https://rail.eecs.berkeley.edu/deeprlcourse-fa23/deeprlcourse-fa23/static/slides/lec-5.pdf

- Maximum likehood 仅仅让 朝着“这批动作出现概率最大”的方向演进.
-
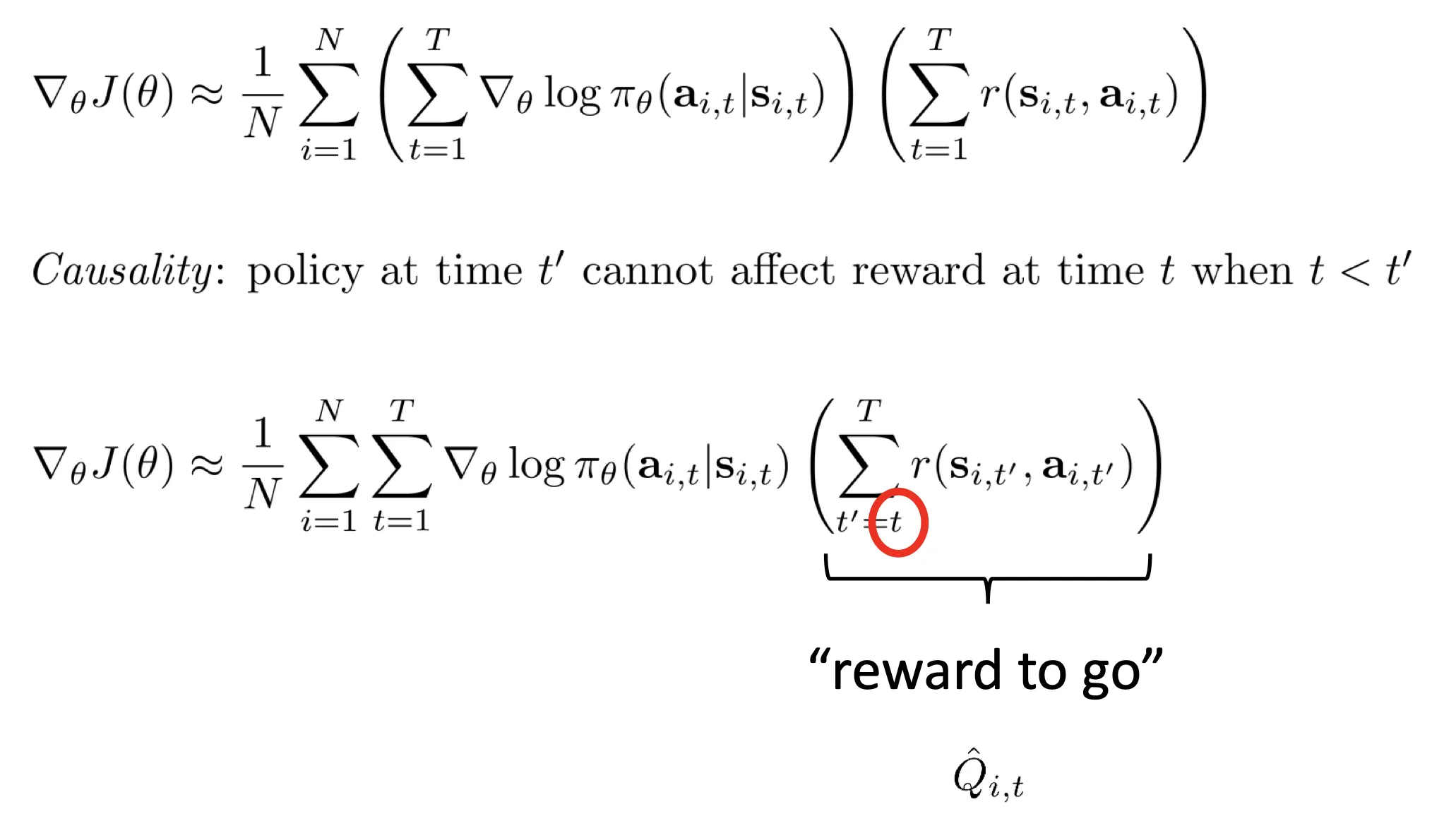
- 问题:奖励方差大,训练效率低下。好轨迹梯度可能为 0(累积奖励 0),有效奖励信号丢失.
- 换种形式: reward to go:
- 等等先换一个话题,我们求一个 baseline 并改写奖励为
,目的是使梯度方差最小。推导出最优的 为:
- 其中:
- 结合以上两个优化,得到:
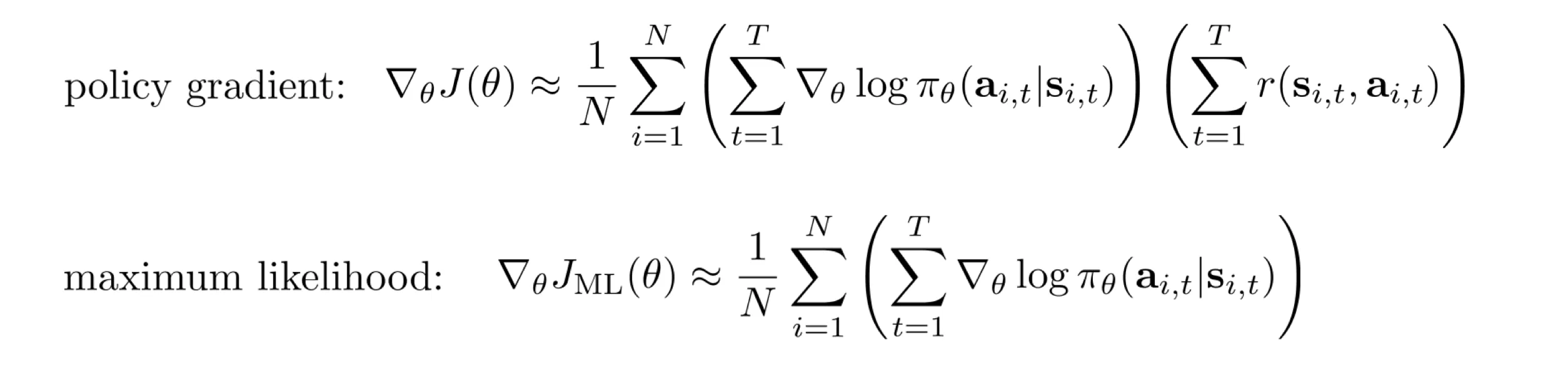
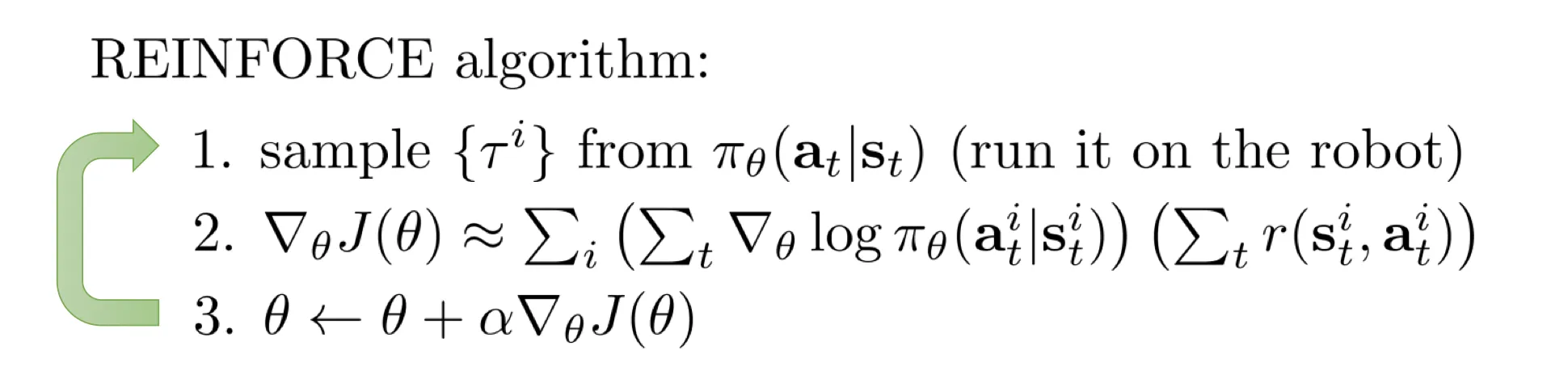
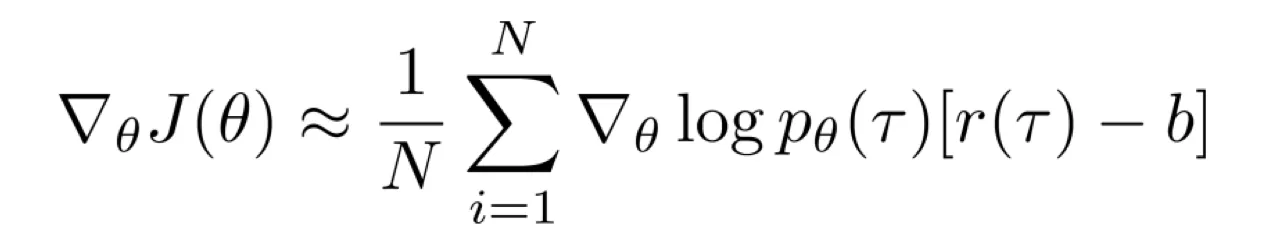 ,目的是使梯度方差最小。推导出最优的 为:
,目的是使梯度方差最小。推导出最优的 为:
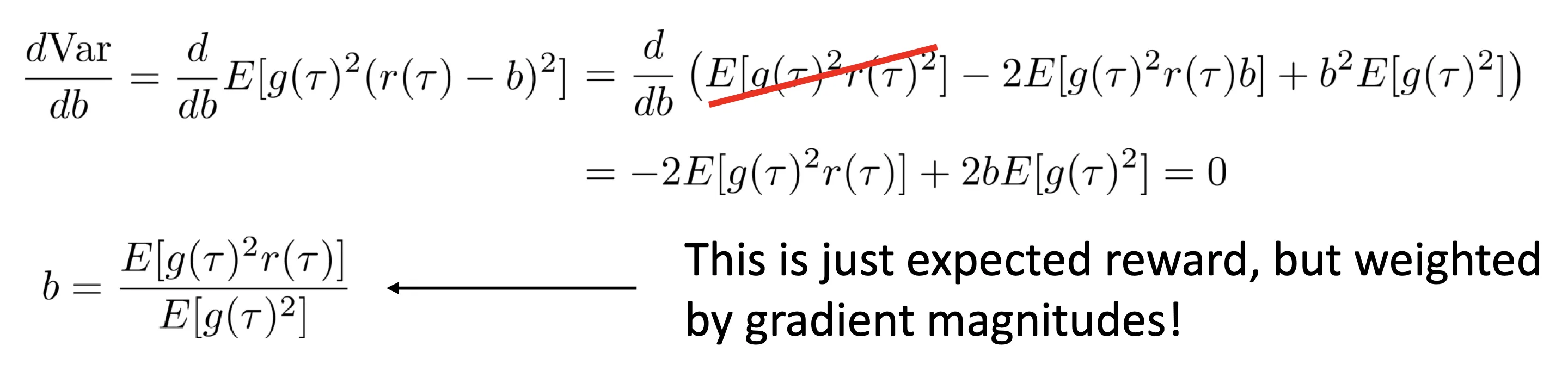
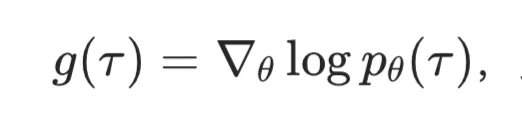
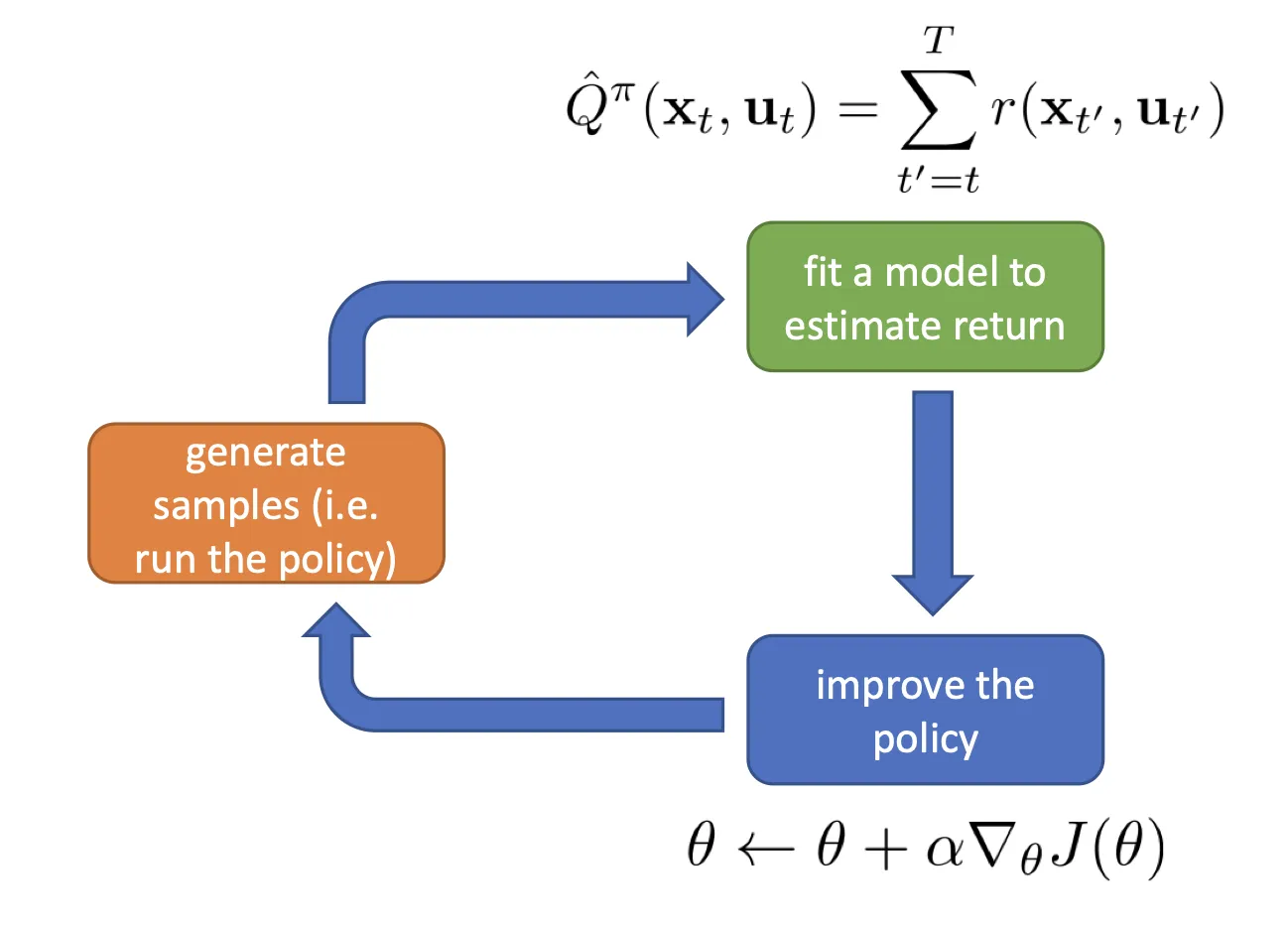
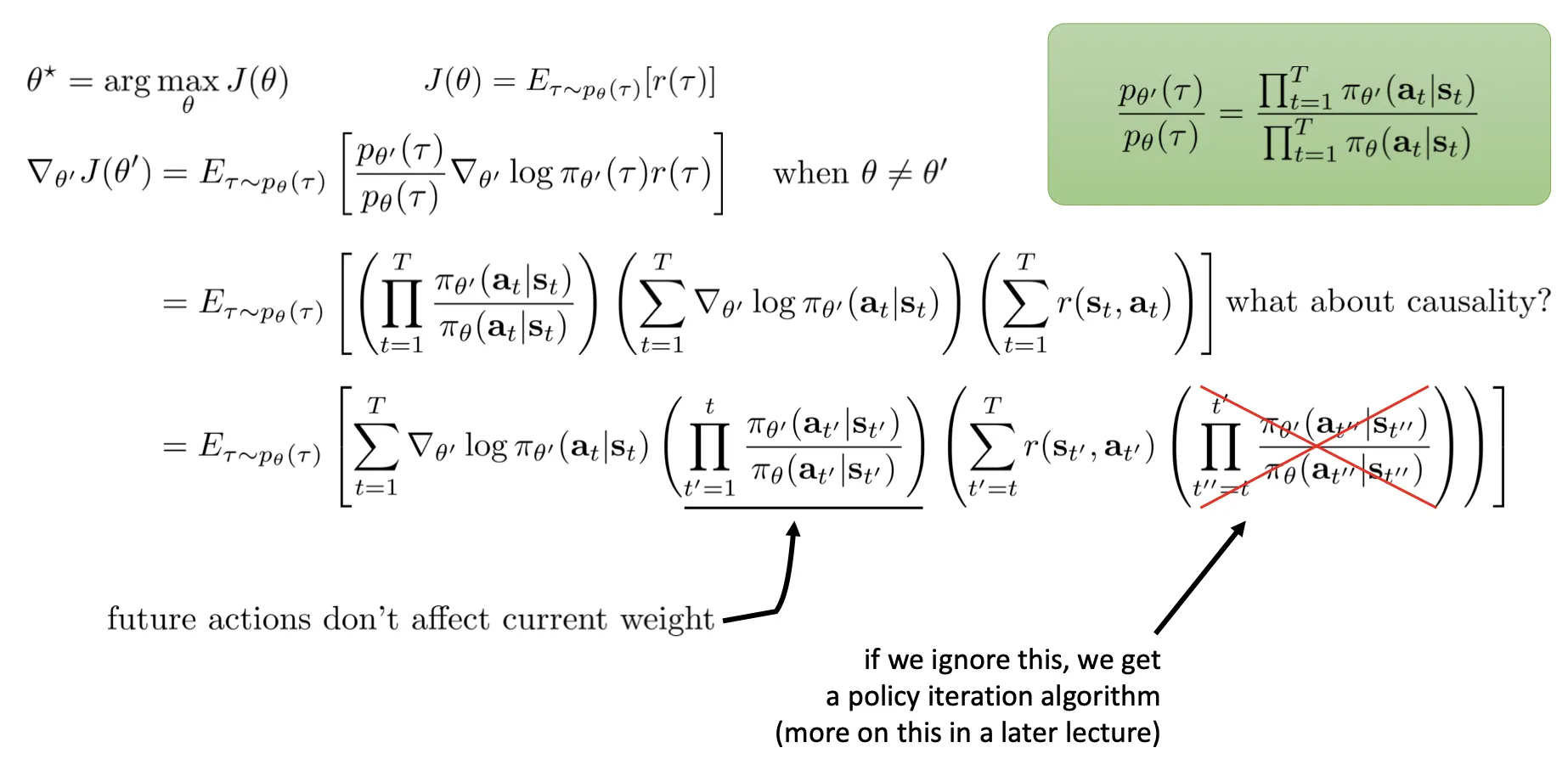
为什么 PG 必须是 on-policy
上述公式是对 求导, 必须是最新的,求的梯度才有意义。导致训练效率很低. 当然你可以多采样几次,相当于 batch 大很多.
importance sampling
- 这个公式就是 IS:
- The Off-policy policy gradient: 这张图简单易懂: