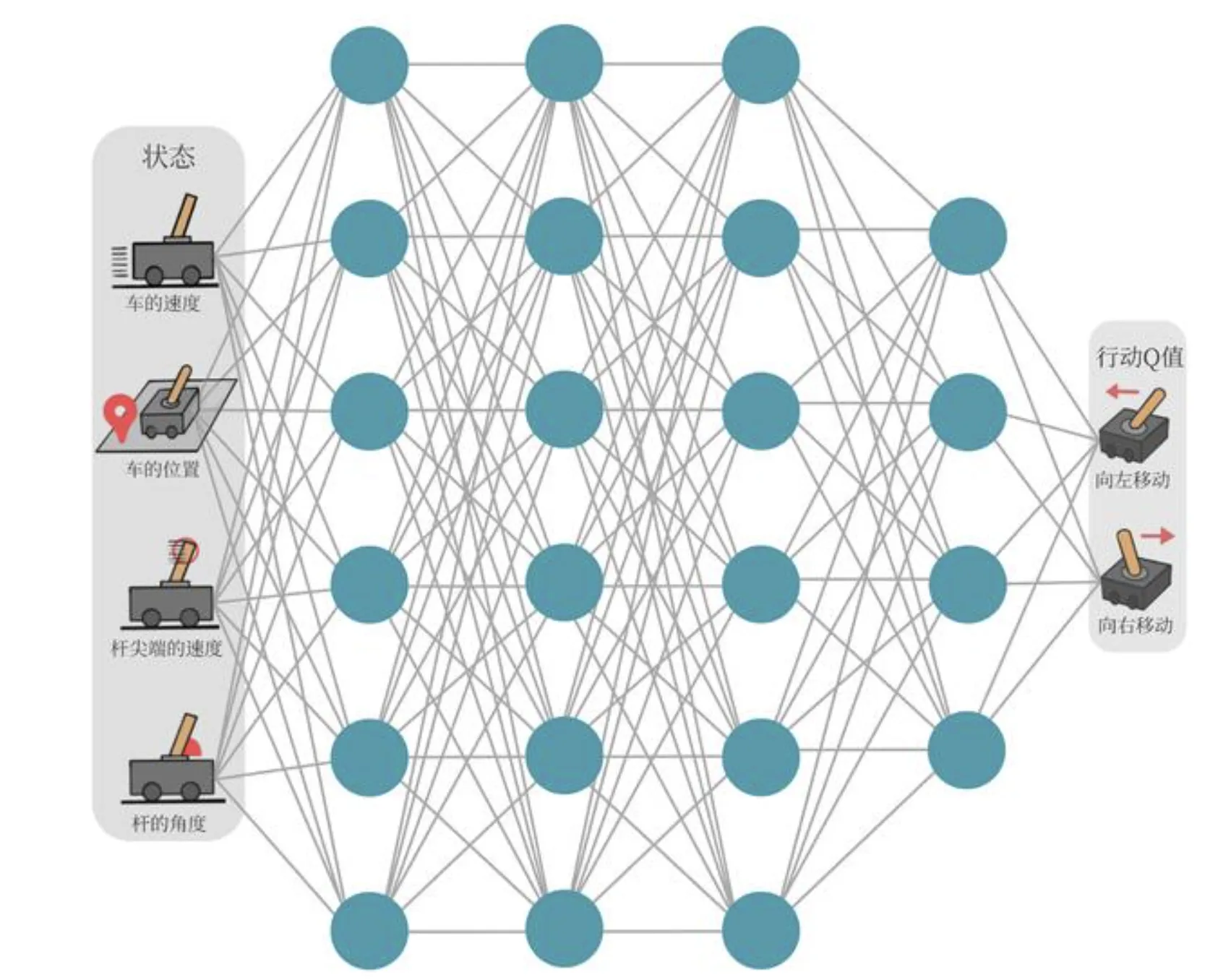
- DQN 作用:对于连续的状态和离散的动作,可通过采样方式更新神经网络
- Input: 可微状态(并不含动作)
- Output: 离散动作的动作价值
- 这就是学了个 ,有了 策略就是选最大价值动作。
- 本章训练环境为小车上平面倒立摆的控制,奖励函数: 坚持 1 帧获得奖励 1,倾斜度数或者偏离程度过大或坚持 200 帧则结束。

损失设计
- 由于 Q-learning 是这样的:
- 所以对于一个批量的采样 ,可以这样设计损失函数:
- 注意下面损失函数里有 本身,无法方便求损失,所以后面设计了双网络(训练网络和目标网络)。这里 是 MLP 权重。
- 损失函数为 时,再训练时满足: 动作奖励函数 = 该动作奖励 + (状态随机采样,动作最优)后续状态下最优动作奖励函数
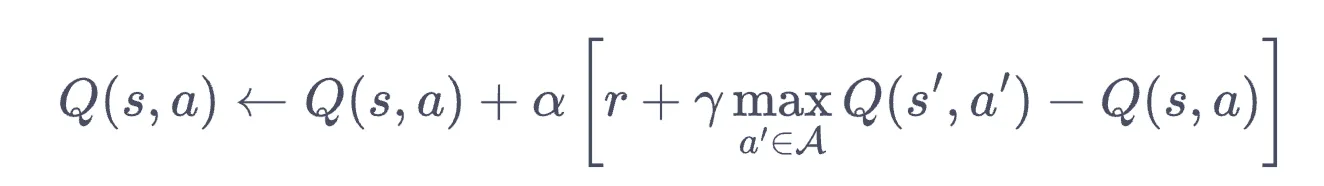
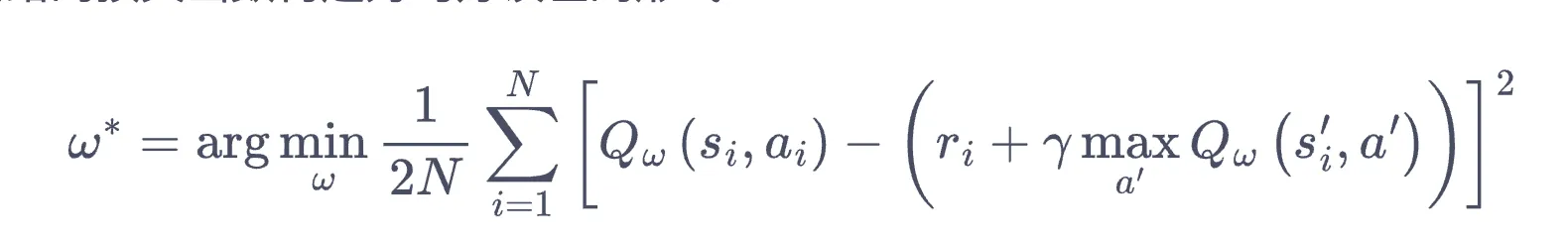
训练细节: 经验回放 experience replay
- 将历次采样放入缓冲区,取缓冲区的若干次数据(而不是最近一次)作为一个小批量来优化
- 整个训练过程中,
replay_buffer不重置,每次训练拿出的数据大小为batch_size
目标网络 + 训练网络
其实就是复制两份网络,训练网络每次批量优化时都会更新(目标网络暂不更新),其中损失函数使用目标网络计算,每隔 步将目标网络同步到训练网络。注意神经网络形式化的损失函数总是 ,在下方原文中可以见到。
- : 目标网络的权重

1# 常规 Q-learning2...3action = agent.take_action(state)4next_state, reward, done = env.step(action)5agent.update(state, action, reward, next_state)6state = next_state7
8class ...:9 def update(self, s0, a0, r, s1):10 td_error = r + self.gamma * self.Q_table[s1].max(11 ) - self.Q_table[s0, a0]12 self.Q_table[s0, a0] += self.alpha * td_error1# DQN2class Qnet(torch.nn.Module):3 def __init__(self, state_dim, hidden_dim, action_dim):4 super(Qnet, self).__init__()5 self.fc1 = torch.nn.Linear(state_dim, hidden_dim)6 self.fc2 = torch.nn.Linear(hidden_dim, action_dim)7
8 def forward(self, x):9 x = F.relu(self.fc1(x))10 return self.fc2(x)11
12class ...:13 def update(self, transition_dict):14 states = torch.tensor(transition_dict['states'],15 dtype=torch.float).to(self.device)43 collapsed lines
16 actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(17 self.device)18 rewards = torch.tensor(transition_dict['rewards'],19 dtype=torch.float).view(-1, 1).to(self.device)20 next_states = torch.tensor(transition_dict['next_states'],21 dtype=torch.float).to(self.device)22 # dones[i]: 第 i 个状态是否为终止状态23 dones = torch.tensor(transition_dict['dones'],24 dtype=torch.float).view(-1, 1).to(self.device)25
26 # q_values: 训练网络给出的 Q值, 作为 y^hat,上面存了梯度27 # `gather`函数用于从输出中选择特定的Q值。`1`表示在第二个维度(动作维度)进行选择,`actions`是动作的索引28 # [q] gather 也能存梯度么?29 q_values = self.q_net(states).gather(1, actions)30 # 下个状态的最大Q值,目标网络给出,这是 y^real 的一部分31 max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)32 q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) # 终止状态不考虑下步奖励33 dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数34 self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为035 dqn_loss.backward() # 反向传播更新参数36 self.optimizer.step()37
38 if self.count % self.target_update == 0:39 self.target_q_net.load_state_dict(40 self.q_net.state_dict()) # 更新目标网络41 self.count += 142
43
44action = agent.take_action(state)45next_state, reward, done, _ = env.step(action)46replay_buffer.add(state, action, reward, next_state, done)47state = next_state48# 当buffer数据的数量超过一定值后,才进行Q网络训练49if replay_buffer.size() > minimal_size:50 b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)51 transition_dict = {52 'states': b_s,53 'actions': b_a,54 'next_states': b_ns,55 'rewards': b_r,56 'dones': b_d57 }58 agent.update(transition_dict)最后输出
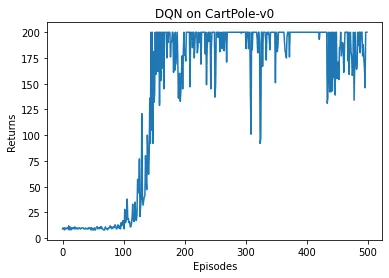
这里输出的每一个值是单个 episode 重置环境后的若干步采样的平均 return。相当于把机器人放到现实环境里去跑了几秒钟。
done.