符号
- : 动作集合 : 奖励概率分布,动作 对应一个奖励分布
- 对动作 ,定义其期望奖励为
- 最优期望奖励
- 懊悔
- : 对 的期望奖励估值
名称
- MAB: 多臂老虎机
- UCB: 上置信界法
问题表述
多臂老虎机是无状态的强化学习,即与环境交互不会改变环境。在下述算法里,每个老虎机的奖励服从伯努利分布,即以 的概率获得
贪心算法
以 的概率随机探索一个。结果由于随机的部分,懊悔是线性增长的。
随时间衰减的 贪心算法
测试时 (老虎机个数),结果累计懊悔是 形式增长的。

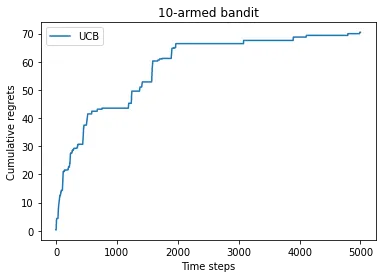
上置信界算法
用到了霍夫丁不等式。每一时刻设一个概率 。对于每个动作 算出一个 s.t. ,根据霍夫丁不等式必有: 至少以 概率成立,称不等式右边为期望奖励上界(其实是大概率上界)。当 增大时该可能性极大。
实操时, ,每次选择 其中 为控制不确定性比重的系数。ipynb 中
累计懊悔也是 形式:
汤普森采样算法
若拉杆 次奖励为 , 次奖励为 ,则大胆假设拉杆的奖励概率(注意奖励概率为 ,每次要么得 要么得 )的概率分布为
那么每步怎么做决策呢?我们已经大胆假设了所有拉杆的奖励的期望的分布,那么就直接对所有拉杆进行一次 分布上的采样。拉动采样最大的那个