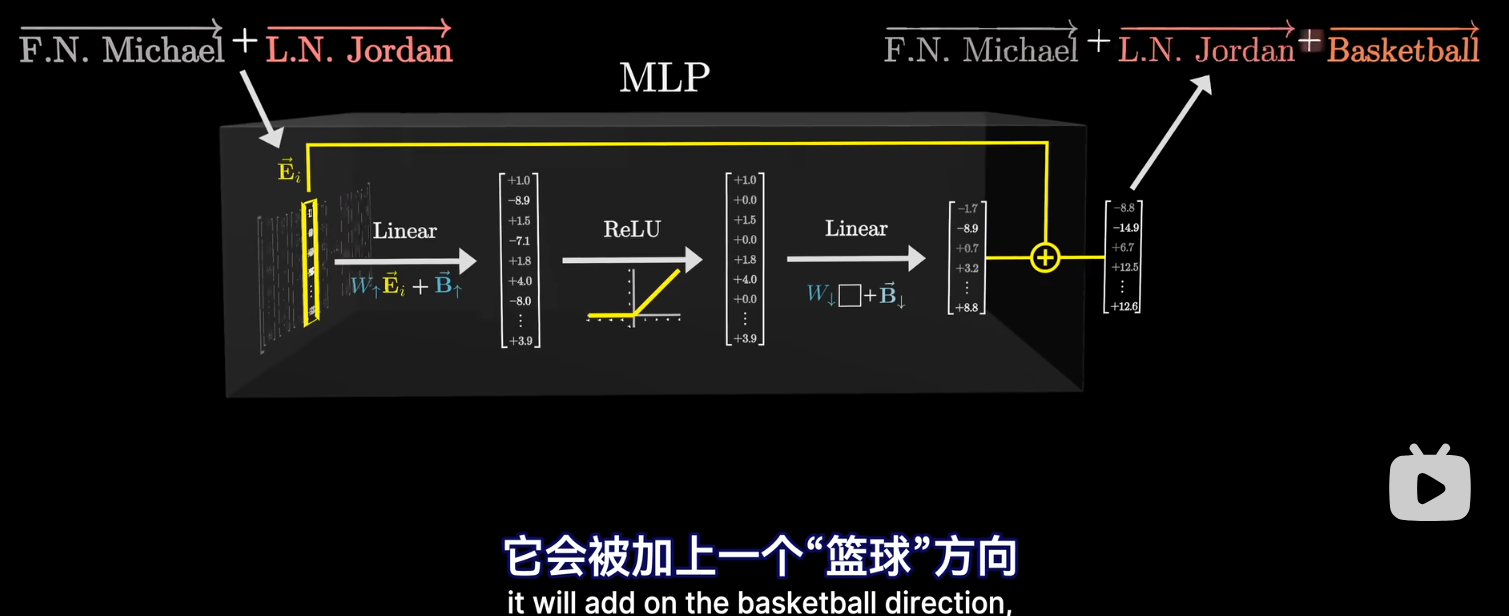
- 结构: Linear + ReLU + Linear
- 假设 Attention 输出的 嵌入维度 10000
- 前半 Linear 矩阵 30000x10000:
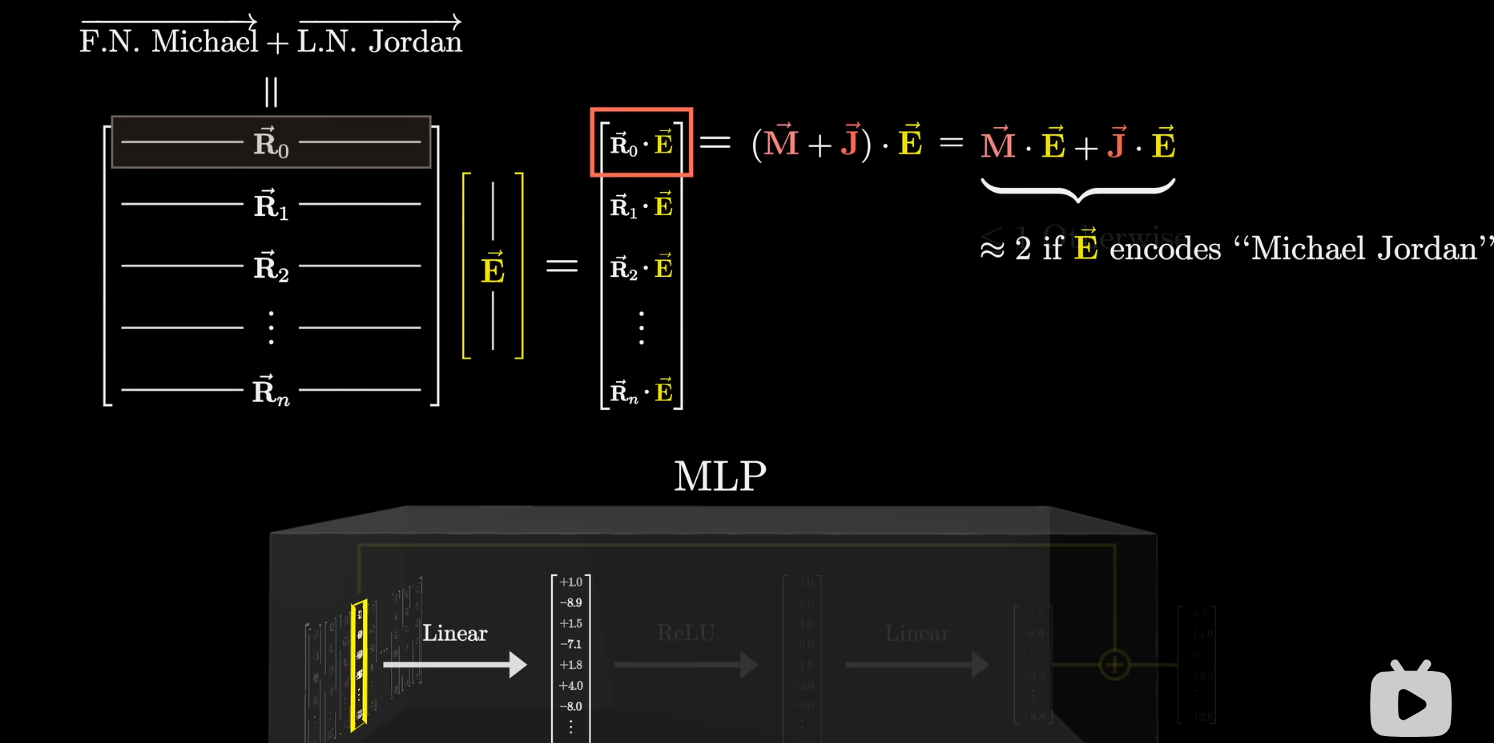
- [e.g.] 第一行 通过点乘查询:这个 是否编码了“Michael Jordan” 的含义?(可包含多个含义)点乘结果直接作为输出向量的第一个元素(红框)。在例子中,若该元素为 则认为完美匹配含义.
- [e.g.] 第二行 通过点乘查询:这个 是否编码了四足动物的含义?
- 后面还有 Bias,每个元素修正一个查询结果. 例如通过 -1 来让第一个点积由 2 变成 1.
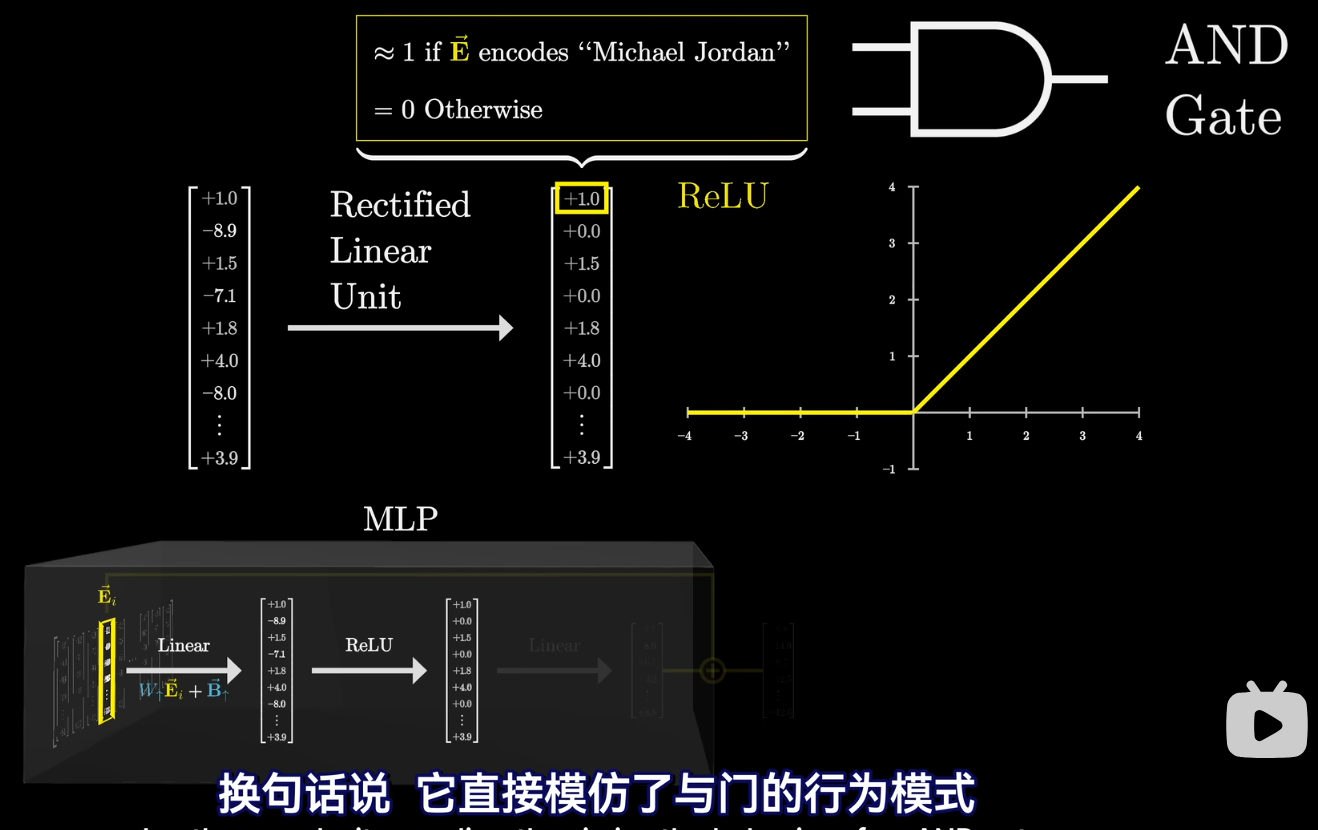
- 中间 ReLU 层:
- 将前面小于 0 的结果直接变 0. 即把大于 0 当作 active,小于 0 当作 inactive.
- 结果升维了,不再是嵌入空间,而是类似于“每一个元素代表一个查询结果”.
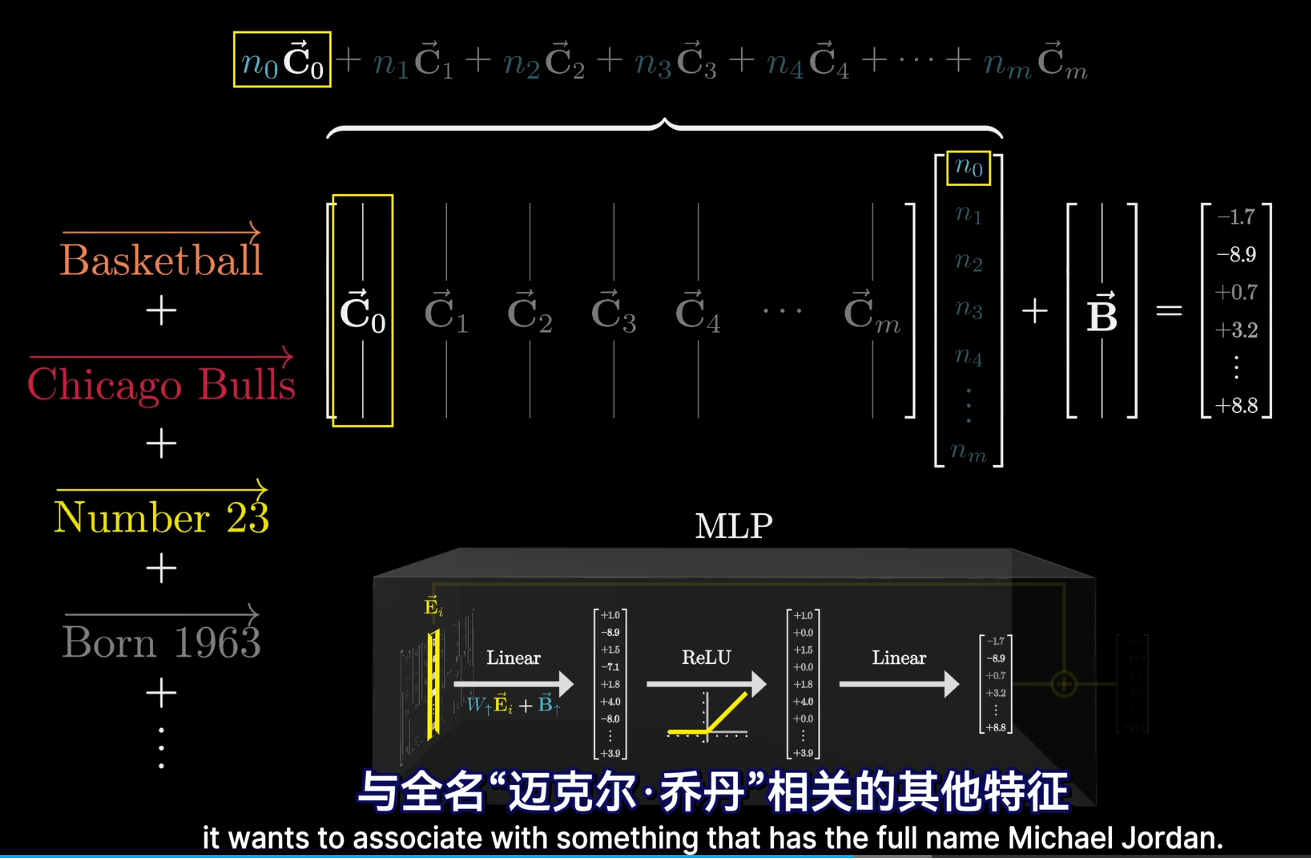
- 后半 Linear 层例如 30000x10000,一定和前半相反:
- [e.g.] 第一列 可以理解为一个嵌入空间中的向量,将第一个查询结果 转换为嵌入空间的向量. 比如 可能在嵌入空间中包含“篮球,数字23”等多个意思!
- 偏置向量可以理解为直接暴力加在结果后的嵌入向量![qm] 我靠,难道意味着一次 MLP 会植入一个信号么?
- 最后通过残差层,将结果加入到开始的输入上. 如最上面的图.
Article title:what-does-MLP-do-3B1B
Article author:Julyfun
Release time:May 18, 2025