- 原网址 https://stanford-cs336.github.io/spring2025/
- 参考笔记 https://yyzhang2025.github.io/posts/CS336/Ass01/ass01.html#tokenize-and-save-file
Utils
6 步走
1x, y = to(device)2opt.zero_grad3out = model(x)4loss = loss(y, out)5loss.backward()6opt.step()7
8log...log
1pbar = tqdm(range(iteration, target_iteration))2for :3 pbar.set_postfix( any dict )4 wandb.log( any dict )Lec 1 BPE
word tokenizer 很少使用了.
BPE Tokenizer: Byte pair
unhappiness => un happi ness
- 词汇表大约几万
Lec 2 torch
- [torch]
1请自行恢复上下文.2? torch.ones(3, 3).triu()3? x.rsqrt()4? x.transpose(1, 0).contiguous() 会复制- [einops]
1We don't write:2 y = x.transpose(0, 2, 3, 1)3We write comprehensible code:4 y = rearrange(x, 'b c h w -> b h w c')5Also:6 rearrange(ims, "b h w c -> h (b w) c").shape7 rearrange(ims, "(b1 b2) h w c -> b1 b2 h w c ", b1=2).shape8 reduce(ims, "b h w c -> h w c", "mean") # Average overbatch9 reduce(ims, "b h w c -> h w", "min")Lec 3 超参
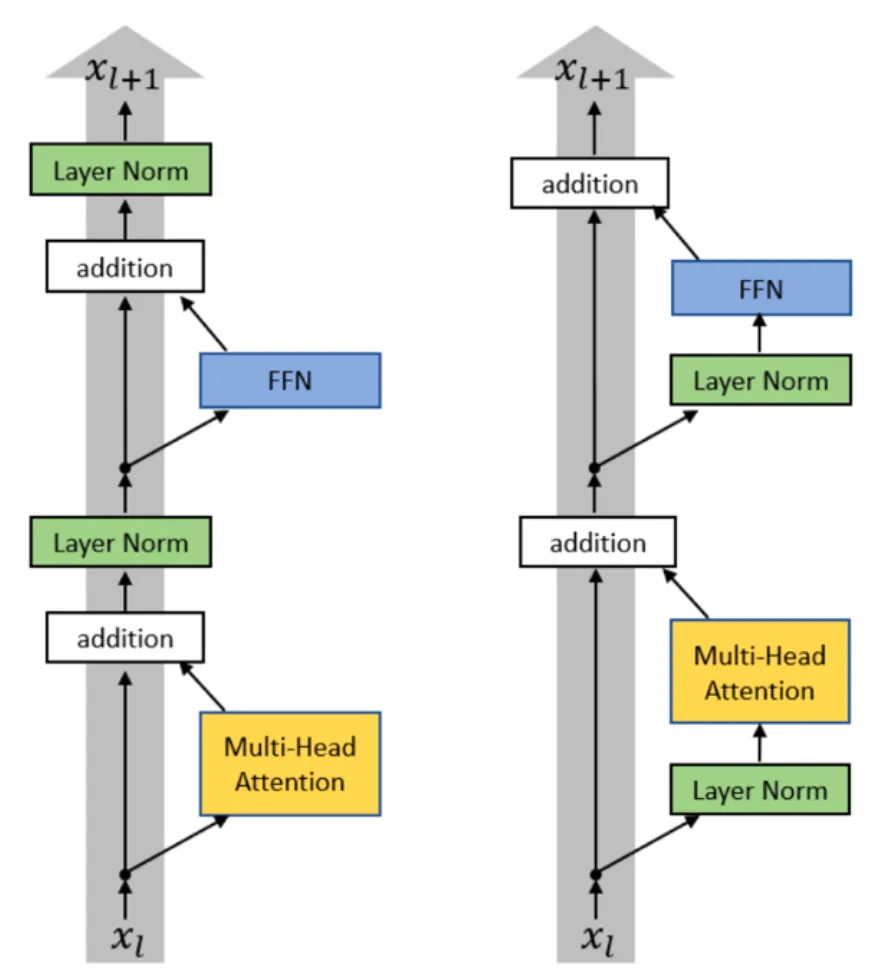
各种选择.pre-post-norm
-
prenorm vs post-norm: 大家都选择 prenorm,不影响 residual path
-
prenorm 实践中更稳定.
-
还有 double norm: 在 prenorm 的 FFN 之后再 LN.
-
下图左边为 post-norm.

各种选择.RMSNorm
- 好处:快
- LN: 减均值除以标准差 * +
- RMSNorm: 除以均方根(球面距离) *
各种选择.GatedLU
FFN = 有点用. V 形状和 W 一样.
各种选择.Parallel
- Standard: y = x + (x + x.LN.Attn).LN.MLP
- Parallel: y = x + x.LN.MLP + x.LN.Attn
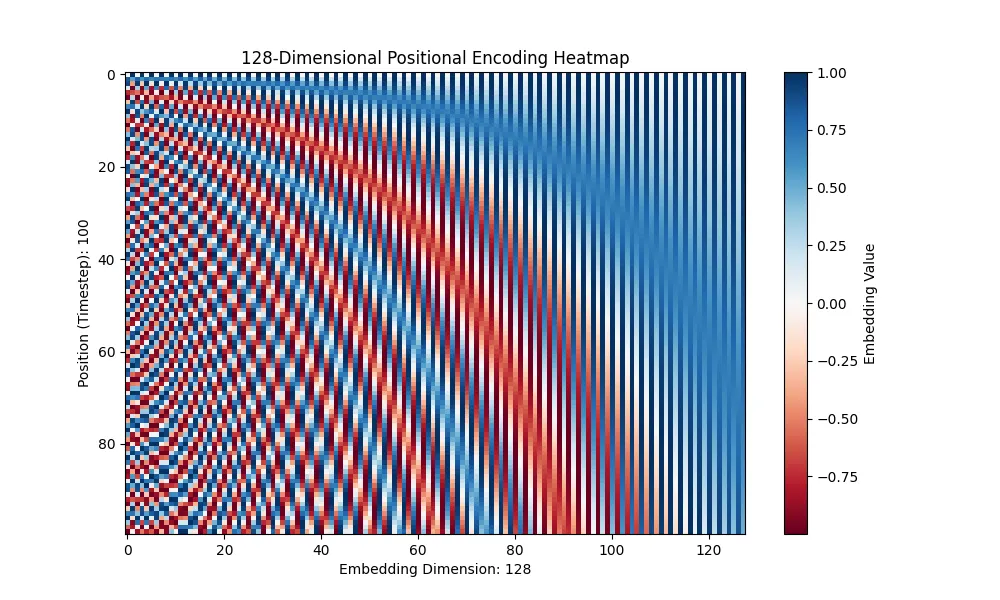
各种选择.位置编码
-
下图每行是一个位置编码. 每列可以看出是周期性的.
-
周期是线性增长的.
-
sine, cosine 依列交错
-
最后一列约为 cosine(pos / 10000)
-
ROPE 这么简单:
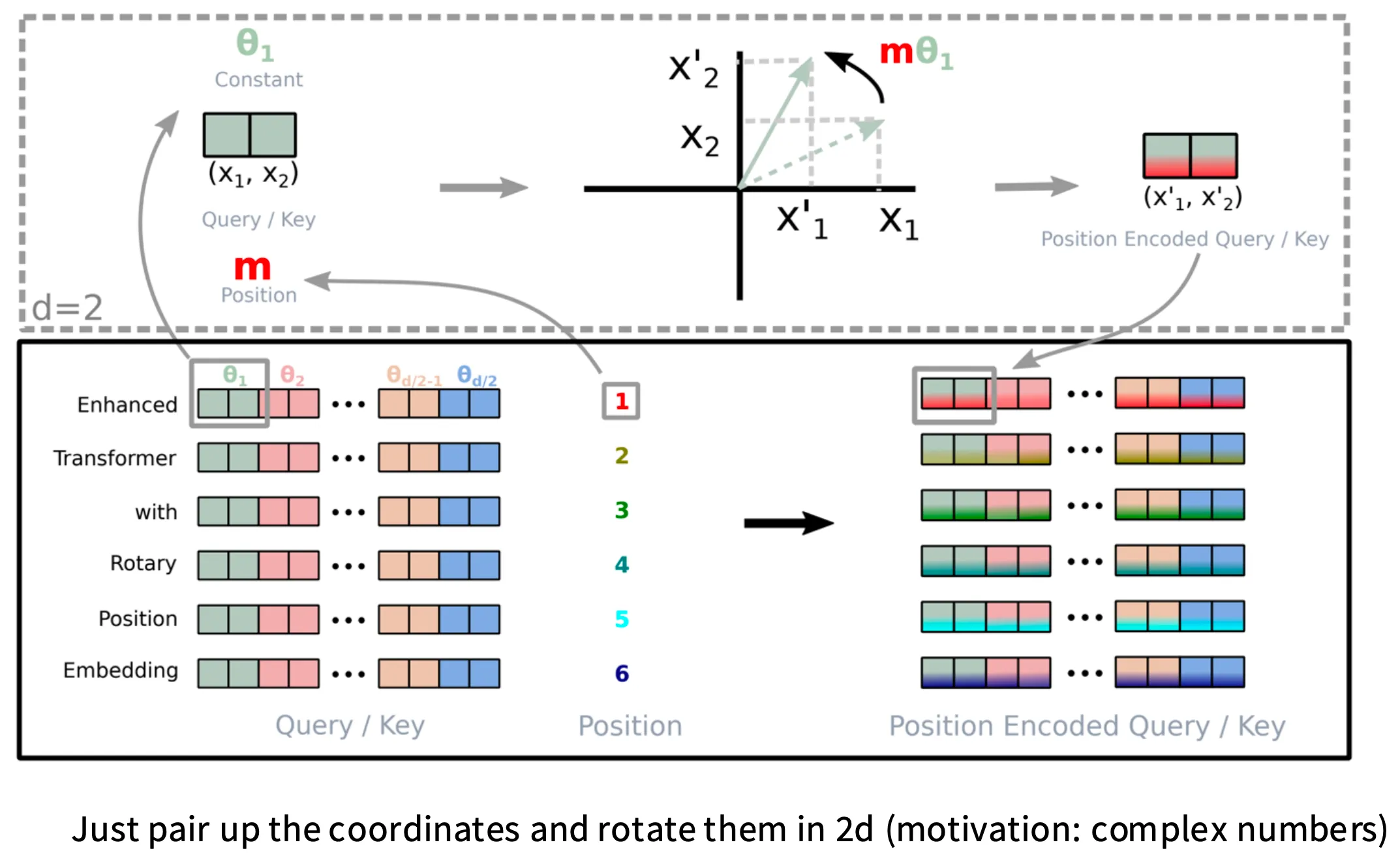
1cos, sin = self.rotary_emb(value_states, position_ids)2query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)各种选择.model-dim
- 定义: d_model 就是 FFN 输入处的向量维度
- d_ff 是 FFN 展开的向量维度,也是隐藏层维度/查询数量
- d_ff / d_model 传统为 4。GLU 为了平衡计算效率(是的,仅此而已),d_ff / d_model 为 8 / 3
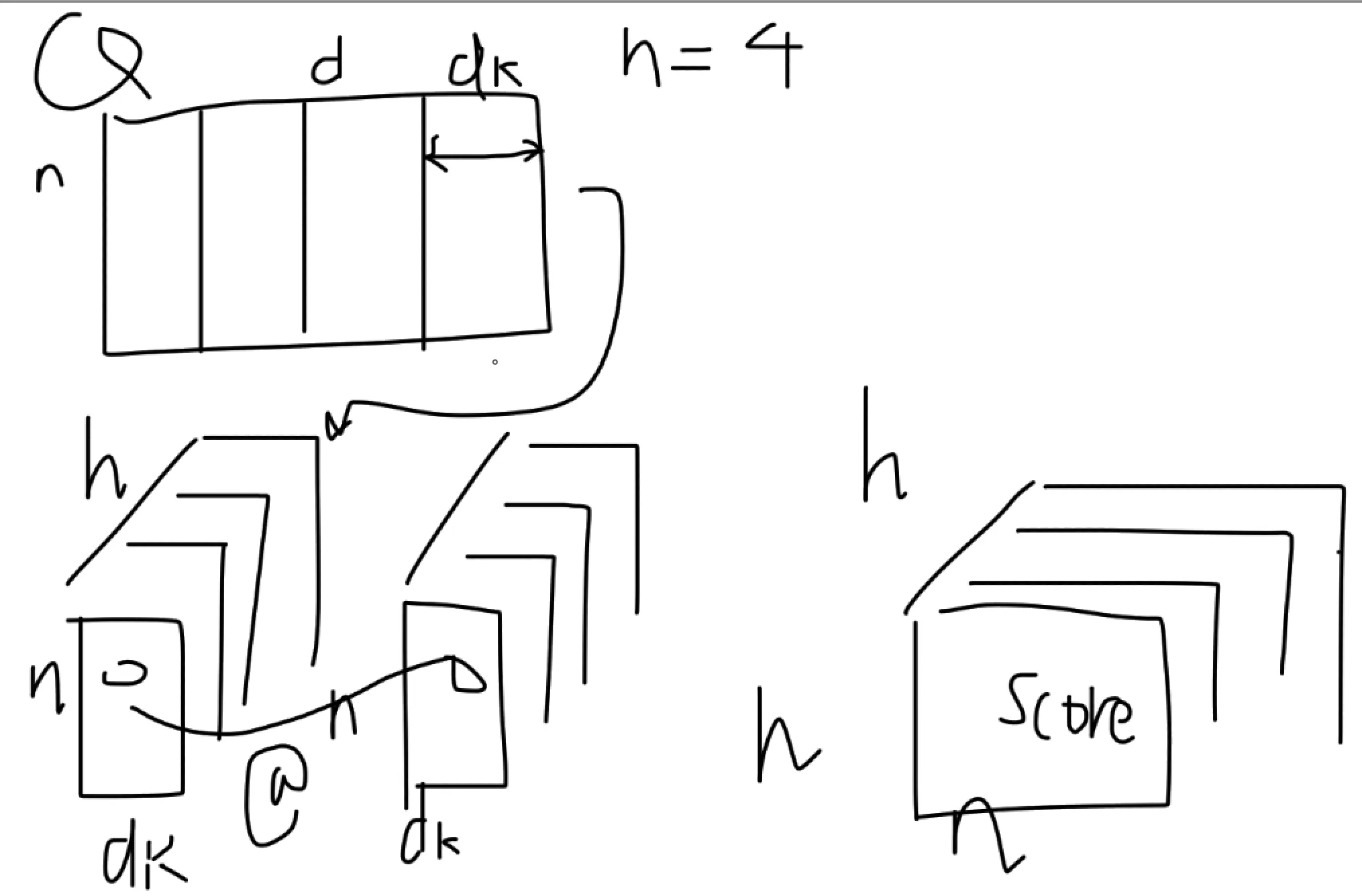
各种选择.attention-head-num
一般 head_dim = model_dim / head_num. 此时运算计算量与不分头完全一样.
1计算量:2b * h * n * n * dk3dk = d / h4=> b * d * n * n (与 h 无关)- [q]:如果一个头只看 d_k 维度,那它是不是漏掉了其他维度的信息?
- [a]: 并不是. 这里的 d_k 是 Q 中的 d_k. 每一个 d_k 里的元素,都是原始 d 维向量的线性组合。只是 attention 被独立分成 num_heads 次.
各种选择.其他
- aspect_ratio: d_model / n_layer
- vocab_size = 40000(monolingual) 200000(multilingual)
- dropout: 0~0.1. weight decay: ~0.1. weight decay 在大语言模型中不防止过拟合,而是只能和 cosine learning rate 配合来略微降低 training loss.
- [todo] softmax z-loss for 稳定性
- [todo] QK norm
- [todo] Logit soft-capping
- Attention heads 大家基本不动.
- Grouped Query Attention, Multi Query Attention..
- Strided Attention, Sliding Window Attetion
Lec 4: MoE
Top-K Routing:
- 将原本的大 FFN 分为 k 个小块专家(计算量不变).
- 每个专家 train-time 训练一个向量 .
- 设输入为 ,则 中选择 topk. 记为
- 然后 u 在这层的输出
- t 是第 t 个 token. l 是第 l 层. i 是第 i 个专家. N 专家数量.
- [todo] Fine-grained ratio
- [todo]
Linear Attention
- 去掉 softmax 的话就可以 Attn = (QK^T)V = Q(K^T V). 这里 Q, K, V 不是QKV矩阵,是已经求出的 q k v 值 (比如 Q 形状 n * d_k)
- 而 K^T * V 计算复杂度是 2 dk dv n, 而且是一个固定大小的矩阵 dk dv.
Sparse Attention
- 跳步 attend