- 原网址 https://stanford-cs336.github.io/spring2025/
- 参考笔记 https://yyzhang2025.github.io/posts/CS336/Ass01/ass01.html#tokenize-and-save-file
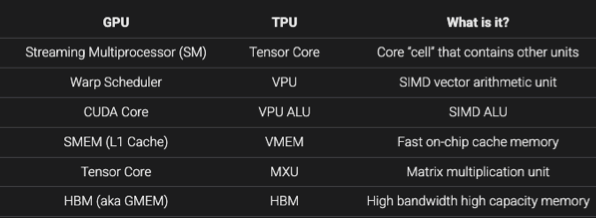
Utils
6 步走
1x, y = to(device)2opt.zero_grad3out = model(x)4loss = loss(y, out)5loss.backward()6opt.step()7
8log...log
1pbar = tqdm(range(iteration, target_iteration))2for :3 pbar.set_postfix( any dict )4 wandb.log( any dict )Lec 1 BPE
word tokenizer 很少使用了.
BPE Tokenizer: Byte pair
unhappiness => un happi ness
- 词汇表大约几万
Lec 2 torch
- [torch]
1请自行恢复上下文.2? torch.ones(3, 3).triu()3? x.rsqrt()4? x.transpose(1, 0).contiguous() 会复制- [einops]
1We don't write:2 y = x.transpose(0, 2, 3, 1)3We write comprehensible code:4 y = rearrange(x, 'b c h w -> b h w c')5Also:6 rearrange(ims, "b h w c -> h (b w) c").shape7 rearrange(ims, "(b1 b2) h w c -> b1 b2 h w c ", b1=2).shape8 reduce(ims, "b h w c -> h w c", "mean") # Average overbatch9 reduce(ims, "b h w c -> h w", "min")Lec 3 超参
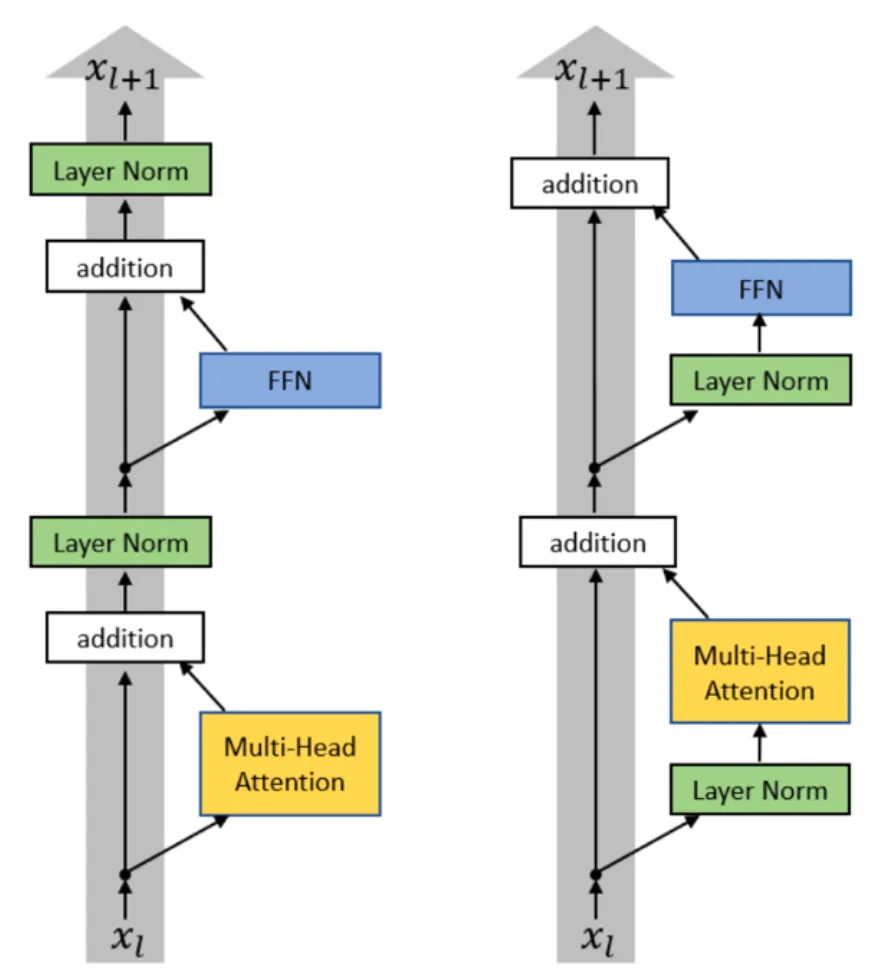
各种选择.pre-post-norm
-
prenorm vs post-norm: 大家都选择 prenorm,不影响 residual path
-
prenorm 实践中更稳定.
-
还有 double norm: 在 prenorm 的 FFN 之后再 LN.
-
下图左边为 post-norm.

各种选择.RMSNorm
- 好处:快
- LN: 减均值除以标准差 * +
- RMSNorm: 除以均方根(球面距离) *
各种选择.GatedLU
FFN = 有点用. V 形状和 W 一样.
各种选择.Parallel
- Standard: y = x + (x + x.LN.Attn).LN.MLP
- Parallel: y = x + x.LN.MLP + x.LN.Attn
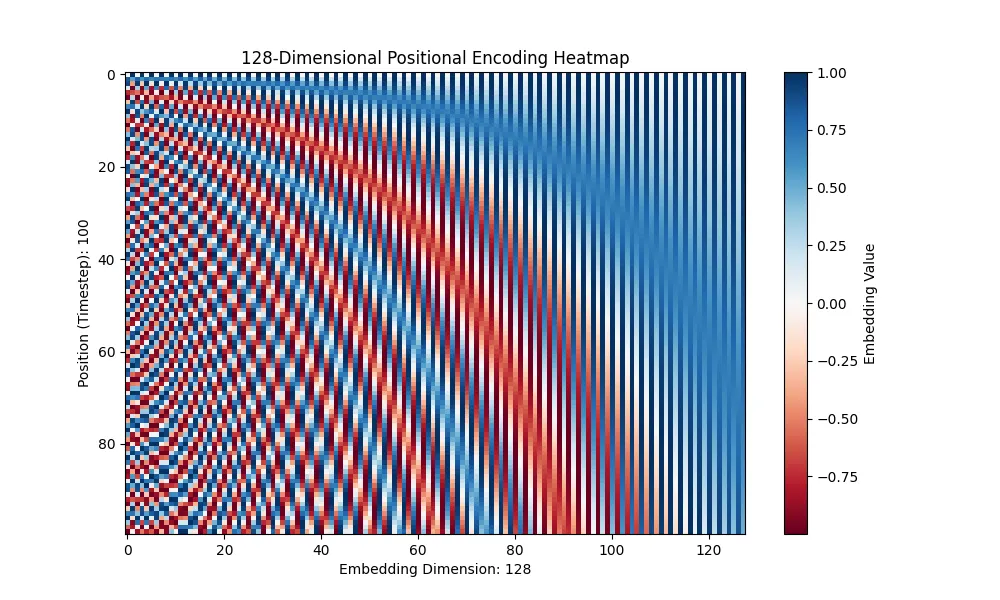
各种选择.位置编码
-
下图每行是一个位置编码. 每列可以看出是周期性的.
-
周期是线性增长的.
-
sine, cosine 依列交错
-
最后一列约为 cosine(pos / 10000)
-
ROPE 这么简单:
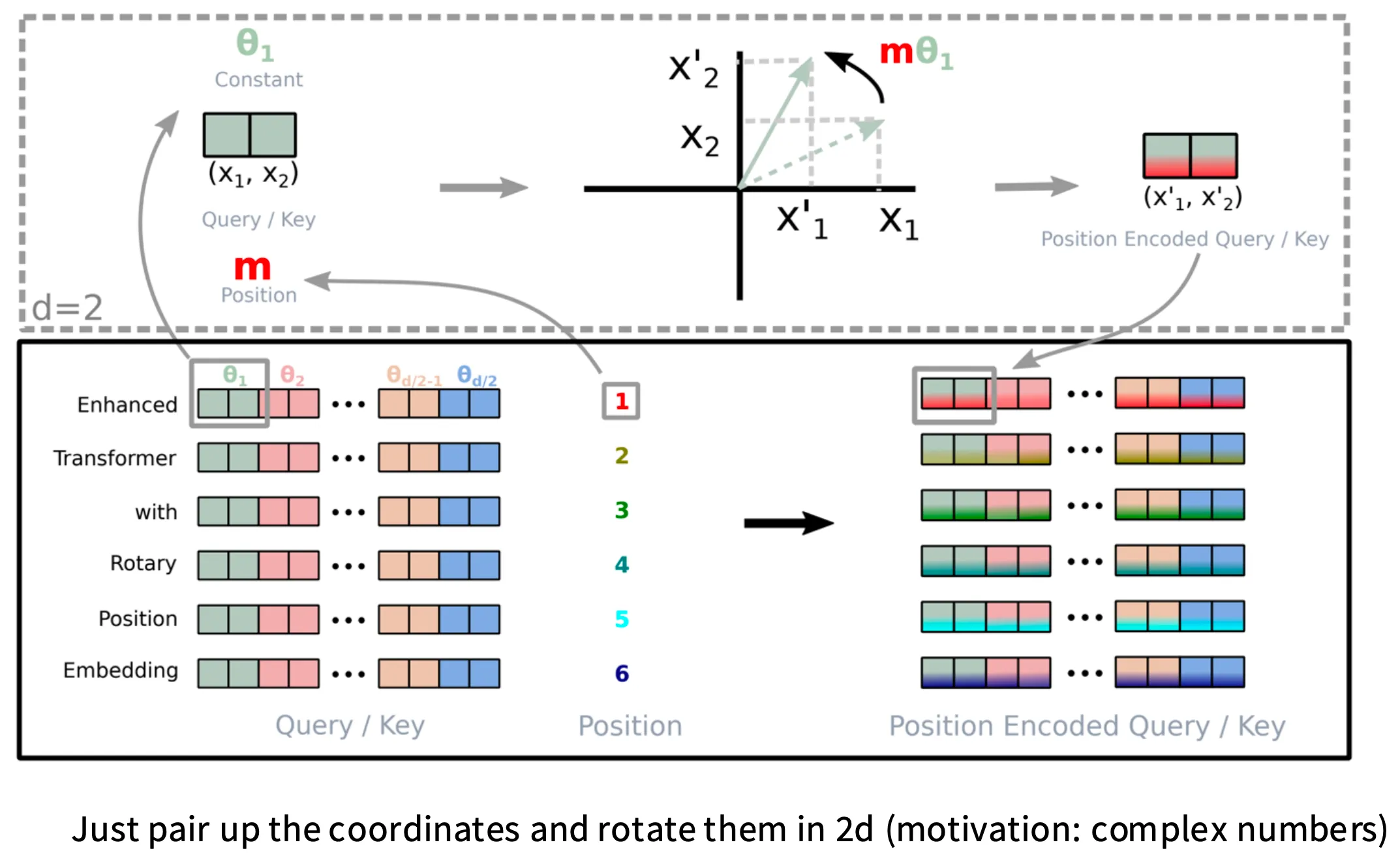
1cos, sin = self.rotary_emb(value_states, position_ids)2query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)各种选择.model-dim
- 定义: d_model 就是 FFN 输入处的向量维度
- d_ff 是 FFN 展开的向量维度,也是隐藏层维度/查询数量
- d_ff / d_model 传统为 4。GLU 为了平衡计算效率(是的,仅此而已),d_ff / d_model 为 8 / 3
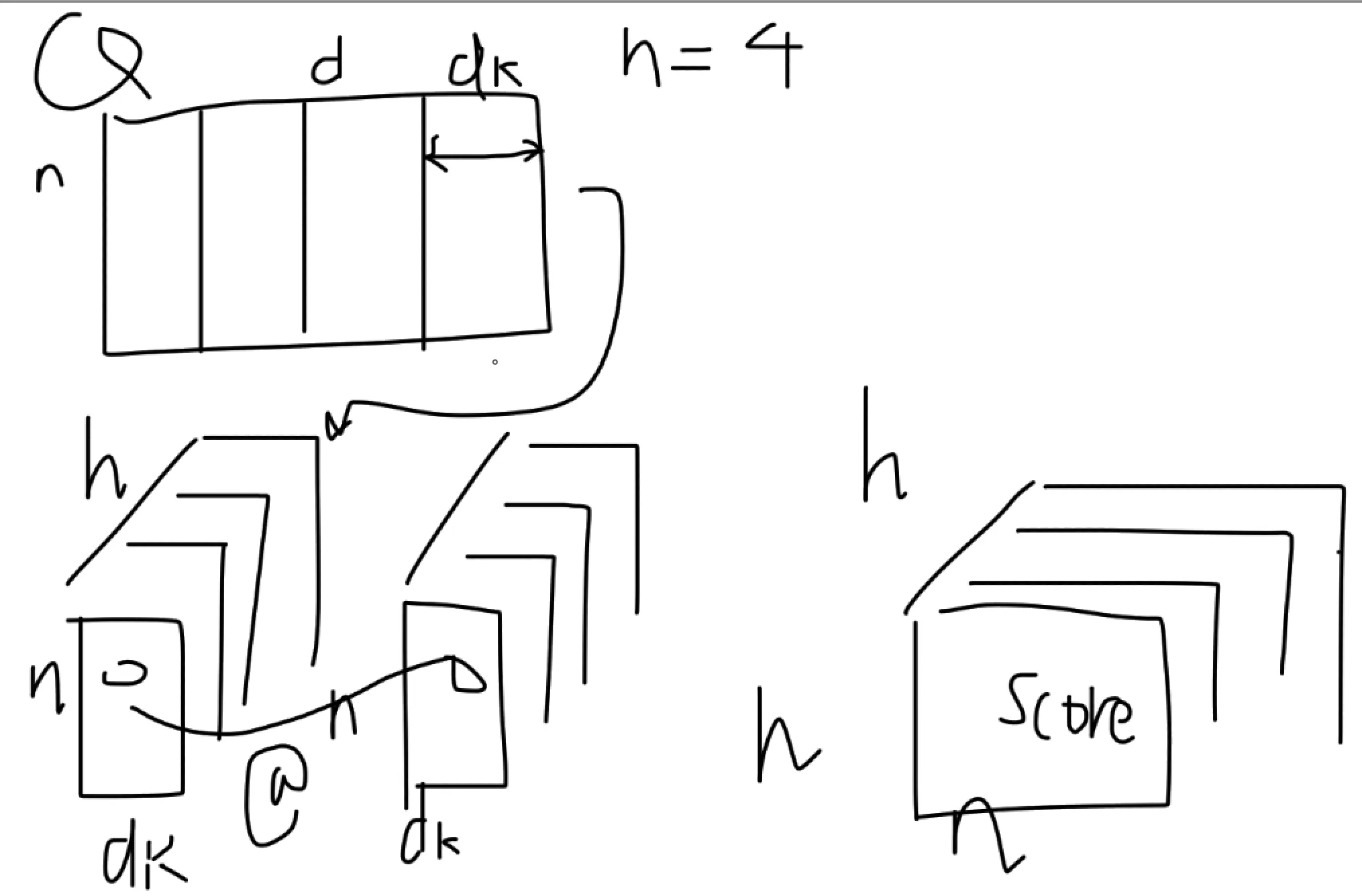
各种选择.attention-head-num
一般 head_dim = model_dim / head_num. 此时运算计算量与不分头完全一样.
1计算量:2b * h * n * n * dk3dk = d / h4=> b * d * n * n (与 h 无关)- [q]:如果一个头只看 d_k 维度,那它是不是漏掉了其他维度的信息?
- [a]: 并不是. 这里的 d_k 是 Q 中的 d_k. 每一个 d_k 里的元素,都是原始 d 维向量的线性组合。只是 attention 被独立分成 num_heads 次.
各种选择.其他
- aspect_ratio: d_model / n_layer
- vocab_size = 40000(monolingual) 200000(multilingual)
- dropout: 0~0.1. weight decay: ~0.1. weight decay 在大语言模型中不防止过拟合,而是只能和 cosine learning rate 配合来略微降低 training loss.
- [todo] softmax z-loss for 稳定性
- [todo] QK norm
- [todo] Logit soft-capping
- Attention heads 大家基本不动.
- Grouped Query Attention, Multi Query Attention..
- Strided Attention, Sliding Window Attetion
Lec 4: MoE
Top-K Routing:
- 将原本的大 FFN 分为 k 个小块专家(计算量不变).
- 每个专家 train-time 训练一个向量 .
- 设输入为 ,则 中选择 topk. 记为
- 然后 u 在这层的输出
- t 是第 t 个 token. l 是第 l 层. i 是第 i 个专家. N 专家数量.
- [todo] Fine-grained ratio
- [todo]
Linear Attention
- 去掉 softmax 的话就可以 Attn = (QK^T)V = Q(K^T V). 这里 Q, K, V 不是QKV矩阵,是已经求出的 q k v 值 (比如 Q 形状 n * d_k)
- 而 K^T * V 计算复杂度是 2 dk dv n, 而且是一个固定大小的矩阵 dk dv.
Sparse Attention
- 跳步 attend
Hw 1:
Problem (unicode1): Understanding Unicode (1 point)
- (a) null character
- (b) string representation: 清晰知道对象是什么. 例如 chr(0) 回车就是 ‘\x00’
- printed 就是
__repr__(),chr(0) 是什么都不显示.
- printed 就是
- (c) chr(0) 在 text 中什么都不占. 只有交互式输出 \x00.
Problem (unicode2): Unicode Encodings (3 points)
- (a): UTF-32 和 UTF-16 比 UTF-8 更长(100:50:34),且有很多的 0,可能不好学.
- (b): 这函数试图把每个 byte 解码为字符了.
1>>> decode_utf8_bytes_to_str_wrong("牛".encode("utf-8"))2UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe7 in position 0: unexpected end of data- (c): unicode 并不是稠密的. [231, 137] 不对应任何 unicode 字符.
1bytes([231, 137]).decode()2# failedProblem (train_bpe): BPE Tokenizer Training (15 points)
最恶心修改:3e90c96
-
调整 PAT 使得多个 \n 能够分到一组
-
调整 special token pattern 使得他们能够吃掉尾随的换行(测试样例里面是这样的我也不知道为什么)
-
Finished in Rust. test ok.
Problem (train_bpe_tinystories): BPE Training on TinyStories (2 points)
/usr/bin/time -v cargo test --release test_re4 -- --nocaptureatc254184
1 Percent of CPU this job got: 1991%2 Elapsed (wall clock) time (h:mm:ss or m:ss): 0:07.703 Maximum resident set size (kbytes): 2247060 也就是 2.2Guv run maturin develop --release --features pyo3-extension && /usr/bin/time -v uv run train_bpe_tinystories.py
1 Percent of CPU this job got: 1505%2 Elapsed (wall clock) time (h:mm:ss or m:ss): 0:10.23 时间限制是 30min,快了 180 倍3 Maximum resident set size (kbytes): 2649476python 版本慢一点,可能是在序列化把。
- 最长
b' responsibility'make sense. - b) Profile: pretokenize 花了六七秒,而 popping 只花 0.5s.
Problem (train_bpe_expts_owt): BPE Training on OpenWebText (2 points)
-
由于 buffer 可能被截断无法转 utf8,这里我把它改成 u8 匹配了。
-
有的 pretoken 居然有 12 万长度,i16 居然不够用,直接改 i64.
-
longest: 19 b’ telecommunications’
-
command time -v uv run train_bpe_expts_owt.py
1 Percent of CPU this job got: 283%2 Elapsed (wall clock) time (h:mm:ss or m:ss): 5:17.273 Maximum resident set size (kbytes): 14715528 (14G)4
5时间限制是 100h,快了 1200 倍6yyzhang2025: ~30minProblem (tokenizer): Implementing the tokenizer (15 points)
- 让 codex 写完了, test ok
Problem (tokenizer_experiments): Experiments with tokenizers (4 points)
- a): What is each tokenizer’s compression ratio (bytes/token)? Tiny: 4.09 Owt: 4.53
- b): What happens if you tokenize your OpenWebText sample with the TinyStories tokenizer?: 压缩率仅剩 3.34
- c): Tiny 的流量: 3506110 bytes/second
- Owt 的流量:3123067 bytes/second
- 预计时间:235303s (65小时)
- d): 词表一共 32000 所以 u16 < 65536 够了
Problem (linear): Implementing the linear module (1 point)
- ok
Problem (embedding): Implement the embedding module (1 point)
- ok
Problem (rmsnorm): Root Mean Square Layer Normalization (1 point)
- ok
Problem (rope): Implement RoPE (2 points)
- ok
Problem (softmax): Implement softmax (1 point)
- ok
Problem (scaled_dot_product_attention): Implement scaled dot-product attention (5 points)
- ok
关于数学记号 和 Linear 参数的关系: Linear in_features 是 b,out_features 是 a
- 或者说 ,原文就有
Problem (multihead_self_attention): Implement causal multi-head self-attention (5 points)
- ok (2 tests)
- 中间卡在哪?
- mask 作为下标不会自动广播,用
.expand_as() - 要先分 heads 再 rope。怎么发现的?发现 test 中只有第一行 match,说明大概率是 positional emb 炸了,然而 rope 测试又通过了,肯定是应用 rope 方法不对.
- mask 作为下标不会自动广播,用
Problem (transformer_block): Implement the Transformer block (3 points)
- 卡在变量写错
Problem (transformer_lm): Implementing the Transformer LM (3 points)
- ok
- 卡在多加了 softmax,顺便重构 token_positions 接口
Problem (transformer_accounting): Transformer LM resource accounting (5 points)
- skip
1 vocab_size=50257,2 context_length=512,3 d_model=1600,4 num_layers=48,5 num_heads=25,6 d_ff=6400,7TransformerLM (2,127,057,600 params)8├── Embedding (80,411,200 params)9├── ModuleList (1,966,233,600 params)10│ ├── TransformerBlock (40,963,200 params)11│ │ ├── MultiheadSelfAttention (10,240,000 params)12│ │ │ ├── Linear (2,560,000 params)13│ │ │ ├── Linear (2,560,000 params)14│ │ │ ├── Linear (2,560,000 params)15│ │ └── Linear (2,560,000 params)45 collapsed lines
16│ │ ├── RMSNorm (1,600 params)17│ │ ├── SwiGLU (30,720,000 params)18│ │ │ ├── Linear (10,240,000 params)19│ │ │ ├── Linear (10,240,000 params)20│ │ └── Linear (10,240,000 params)21│ │ ├── RMSNorm (1,600 params)22│ └── RotaryPositionalEmbedding23│ ├── TransformerBlock (40,963,200 params)24
25
26context length 改为 512:27TransformerLM (2,127,057,600 params)28├── Embedding (80,411,200 params)29├── ModuleList (1,966,233,600 params)30│ ├── TransformerBlock (40,963,200 params)31│ │ ├── MultiheadSelfAttention (10,240,000 params)32│ │ │ ├── Linear (2,560,000 params)33│ │ │ ├── Linear (2,560,000 params)34│ │ │ ├── Linear (2,560,000 params)35│ │ └── Linear (2,560,000 params)36│ │ ├── RMSNorm (1,600 params)37│ │ ├── SwiGLU (30,720,000 params)38│ │ │ ├── Linear (10,240,000 params)39│ │ │ ├── Linear (10,240,000 params)40│ │ └── Linear (10,240,000 params)41│ │ ├── RMSNorm (1,600 params)42│ └── RotaryPositionalEmbedding43│ ├── TransformerBlock (40,963,200 params)44
45参数量并不会变化46唯一计算量 n 方增长的函数:计算 self attention47
48def scaled_dot_product_attention(49 q: Float[Tensor, "b ... seq_len d_k"],50 k: Float[Tensor, "b ... seq_len d_k"],51 v: Float[Tensor, "b ... seq_len d_v"],52 mask: Bool[Tensor, "b ... seq_len seq_len"] | None,53) -> Float[Tensor, "b ... seq_len d_v"]:54 d_k = q.shape[-1]55 attn = q @ k.mT / d_k ** 0.5 # [b, ..., q_len, k_len]56 if mask is not None:57 mask = mask.expand_as(attn)58 attn[~mask] -= float('inf')59 # v: k_len, d_v60 return softmax(attn, dim=-1) @ vProblem (cross_entropy): Implement Cross entropy
- use LogSumExp
- 卡时间在:维度没搞对(用 gather,以及 sum 默认求所有维度平均),以及自己推公式中间漏 log
Problem (learning_rate_tuning): Tuning the learning rate (1 point)
- 在 toy SGD 总,lr=1, 1e1, 1e2 依次收敛加快,而 1e3 发散.
see
/toy/sgd.py
Problem (adamw): Implement AdamW (2 points)
- test ok
Problem (adamwAccounting): Resource accounting for training with AdamW
- skip
Problem (learning_rate_schedule): Implement cosine learning rate schedule with warmup
- test ok
Problem (gradient_clipping): Implement gradient clipping (1 point)
- 对整个网络所有参数求 l2 norm,如果超过 limit 则缩放一个统一参数使得所有参数 l2 norm 为 limit.
- test ok
Problem (data_loading): Implement data loading (2 points)
- test ok
Problem (checkpointing): Implement model checkpointing (1 point)
- test ok
Problem (training_together): Put it together (4 points)
- ok (no test)
Problem (decoding): Decoding (3 points)
- ok (no test)
Problem (experiment_log): Experiment logging (3 points)
- ok (no test)
- 差不多得了
Lec 5 GPUs
GPU 结构
硬件层:
- GPU
- 1 GPU = 多个 SM (streaming multiprocessor)
- 1 SM = 4 warp schedulers
- 1 SM = 多个 SP (streaming processor)
应用层(被动态分配到硬件层):
- 1 cuda app
- 1 app =4096 blocks (每个动态分配到一个 SM)
- 1 block 有自己的 shared memory
- 1 block = 8 warps
- 1 warp = 32 threads
- 1 thread 有自己的 register
- 多个 blocks in 1 grid (这 grid 是硬件吗)
- 1 grid 有自己的 global memory(CPU DRAM) 和 constant memory
优化技巧 1: 低精度运算
- 前沿 : MXFP8
- 关于量化:
- 所有权重包括FFN 和 QKV 矩阵都支持 fp32 到 fp8 量化吗?
- [gemini] yes。但部分最终层 head 可能保留
- 大概多少数据共享一个 scailing factor? 相邻数据的数量级在实际模型中会比较接近吗(否则就没法相邻数据用 scailing factor吧)?
- [gemini] (1x32) 或者 (32x1)
- 在模型训练或存储时,编译器会进行重排,尽量让数值相关性强的权重放在同一个 Tile(块)里
优化技巧 2: Operator fusion 算子融合
- Computing sin2𝑥 + cos2 𝑥 naively launches 5 CUDA kernels (back and forth)
- ‘Easy’ fusions like this can be done automatically by compilers (torch.compile)
优化技巧3: recomputing 不要缓存
三个连续的 sigmoid,forward 进行 3 次 write(存梯度),backward 进行 3 次 read(取梯度),浪费带宽。不如直接不存梯度,反向传播的时候从 x 开始重新直接算梯度
优化技巧4 : Memory coalescing with DRAM
- ? For row-major matrices – threads that move along rows are not coalesced. Note how the second diagram reads the entire vector at each step!
Trick 5 (the big one): tiling 矩阵分块
一种提升缓存效率的方法.
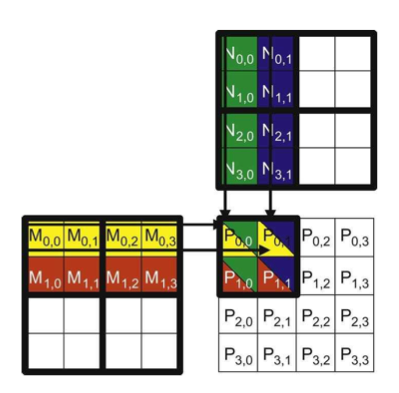
Matrix mystery
Part 1: tiling: 矩阵形状最好是 2^n,比如64比4更好
Part 2: wave quantization: 矩阵从1792x1792到 1793x1793, tile 数量增加到刚好超出A100的SM数量,导致A100无法同时执行所有的 tiles.
Flash attn
- Tiling part 1: tiling for the KQV matrix multiply
- Tiling part 2: incremental computation of the softmax (telescoping sum trick)
SM 的 shm 和 L1 的区别:shm 由程序员手动控制,而 L1 不可见.
Lec6 Tritons:
上节课补充:
- All threads within a warp must execute same instructions in lockstep on an SM. if different threads in a warp need to execute different instructions (if A, else B), must be done sequentially (bad)
- SM 的 warp 调度器支持异步(例如一个 warp 被 IO 阻塞了)
- SM occupancy 指的是 实际调度的 warp 数(随着可变的 num_registers_per_thread 变化,受限于出厂固定的 num_threads_per_block 和 max_registers_per_sm) / SM 支持的 warp 调度器数量. 这个 occupancy 低不一定坏
Lec9 S C A L I N G L A W S
- skip most of this part
HW3 4 5
-
- 简单 scailing law
-
- 数据清洗
-
- PPO/RL (GRPO)
Lec 10
- 标准 grouped query transformer 字母图: https://cs336.stanford.edu/lectures?trace=lecture_10&step=47