自注意力
-
考虑:
- mole 一词在不同上下文有不同含义.
- 嵌入层将 mole 转换为泛型向量以后,Transformer 的下一层会根据上下文再加一个偏移向量。
-
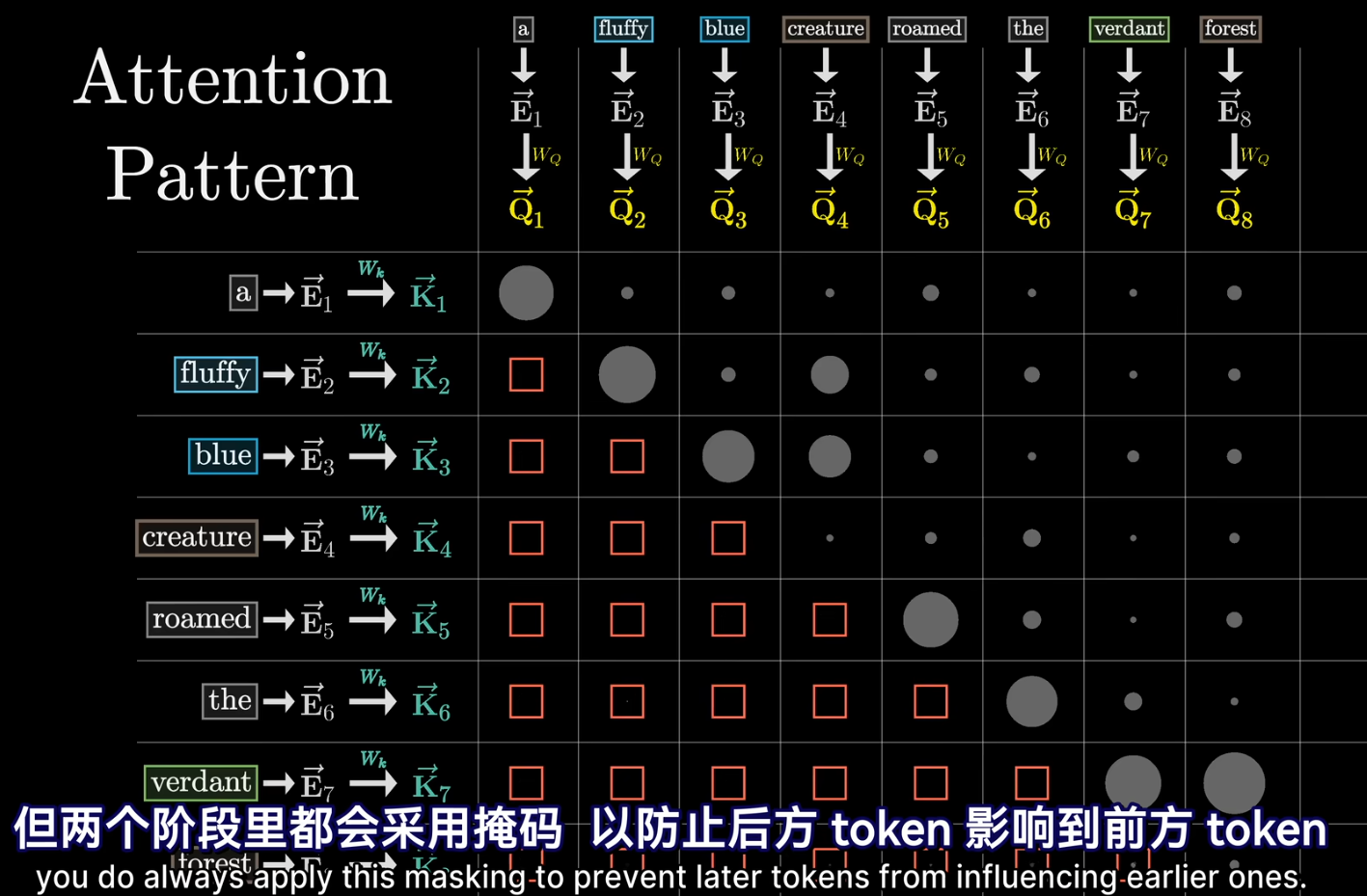
$E_1^->$ 是词嵌入 $+$ 位置嵌入.
- $Q_i^-> = W_Q dot E_i^->$ 形象比喻:$E_1^->$ 是第四个单词,且是名词。问在第四个单词前面有形容词不?
- $K_i^-> = W_k dot E_i^->$ 形象比喻:$E_2^->$ 是第二个单词,形容词。(可以回答上面的询问)
- 上面这张表叫做 Attention Pattern。在从前往后生成文本的任务中,左下角掩码强制置 0,这样前面 Qi 查不到后面 Ki.(在翻译等任务中,则不需要此掩码)
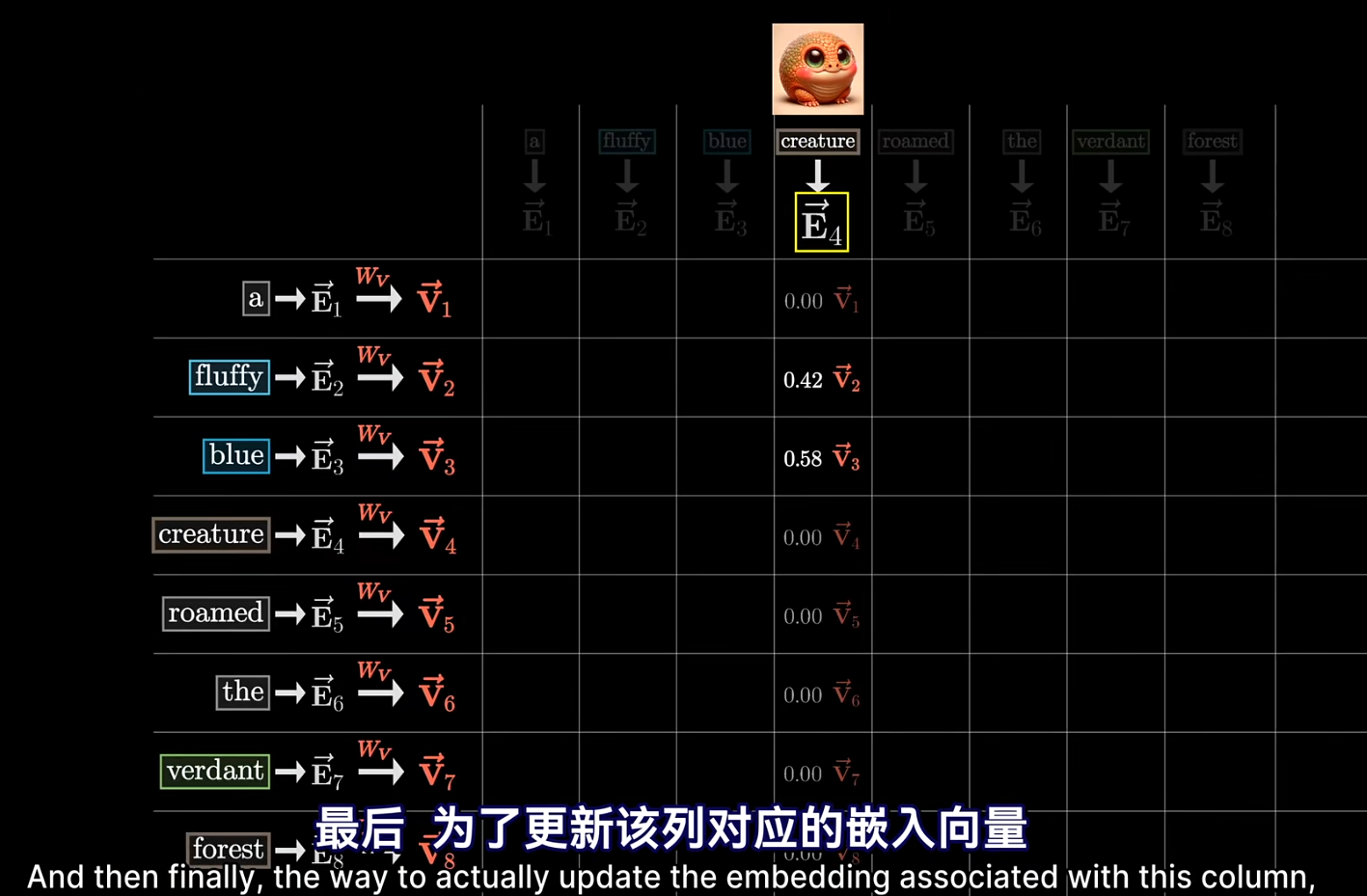
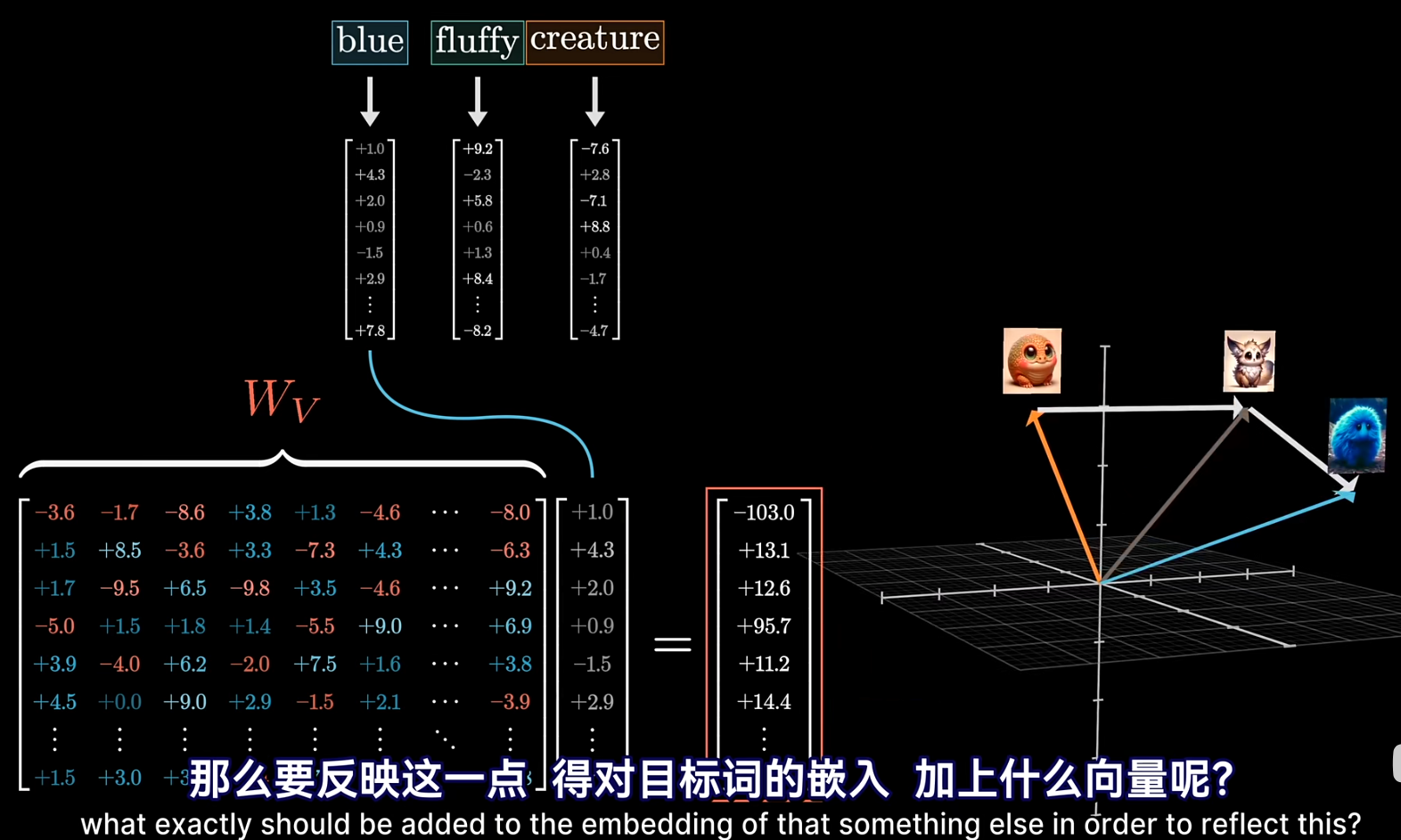
- $V_i^-> = W_v dot E_i^->$ 表示对其他词应该造成什么偏置。比如上图从 creature 到蓝色毛茸茸生物的灰色箭头.
- 这里如果真用 $W_v$ 这个矩阵的话,唯独就爆炸了. 我们先编码再解码,实际上 $V_i^-> = W_(v, "up") dot W_(v, "down") dot E_i^->$
- PS:
- $W_q, W_k$ 和两个 $W_v$ 是一样参数量. GPT-3 中是 $128 times 12288$ ($W_(v, "up")$ 为 $12288 times 128$)
- 经过注意力以后的嵌入结果:加起来,如下图。下面 $Delta E_i^->$ 就是一个注意力.

多头注意力
- 其实就是有 n 组上面这写矩阵,自行学习不同的注意力机制. 比如除了“形容词-名词”修饰,还有可能是“名词推测”、“动作导致形状变化”等注意力机制。GPT-3 中是 96 个头.
- 最后的嵌入结果就是加在一起.

多层多头注意力
- 每次经过一个多头 Attention 以后会过 MLP,然后再过多头 Attention,重复多层. GPT-3 中是 96 层.

交叉注意力
- 文本和图像做交叉注意力时,
- 文本 $==>^("CLIP or BERT")$ Embedding。随后计算 KV.
- 图像 $==>^("resnet 等")$ Embedding, 然后计算 Q.
- 这是文本到图像的注意力,即通过文本得到图像中文本对应的内容,并将其给予更高的权重.
- [AI] PS:
- Q 来自图像,K/V 来自文本 → 这是一个从图像“查询”文本的过程。
- 注意力权重反映的是“图像需要从文本中获取什么信息”
- 猫区域的 Q 与“cat”的 K 相似度高 → 这些区域的注意力权重较大。
- 最终,来自文本 V 的“猫”语义被注入到图像中猫的区域.
- [AI] PS:
- 以下代码来自: GitHub/RoboTwin/policy/3D-Diffusion-Policy/3D-Diffusion-Policy/diffusion_policy_3d/model/diffusion/conditional_unet1d.py
- 可以看出输入被用来计算 Q,而 condition 被用来计算 K, Q
class CrossAttention(nn.Module):
def __init__(self, in_dim, cond_dim, out_dim):
super().__init__()
self.query_proj = nn.Linear(in_dim, out_dim)
self.key_proj = nn.Linear(cond_dim, out_dim)
self.value_proj = nn.Linear(cond_dim, out_dim)
def forward(self, x, cond):
# x: [batch_size, t_act, in_dim]
# cond: [batch_size, t_obs, cond_dim]
# 下面 horizon 就是 t_act.
# Project x and cond to query, key, and value
# 注意 nn.Linear 是右乘,即 x @ weights.T
# weights 形状为 out_dim * in_dim(和创建时相反)
query = self.query_proj(x) # [batch_size, horizon, out_dim]
key = self.key_proj(cond) # [batch_size, horizon, out_dim]
value = self.value_proj(cond) # [batch_size, horizon, out_dim]
# Compute attention
attn_weights = torch.matmul(query, key.transpose(-2, -1)) # [batch_size, horizon, horizon]
attn_weights = F.softmax(attn_weights, dim=-1)
# Apply attention
attn_output = torch.matmul(attn_weights, value) # [batch_size, horizon, out_dim]
return attn_output
多层多头注意力
- 每次经过一个多头 Attention 以后会过 MLP,然后再过多头 Attention,重复多层.