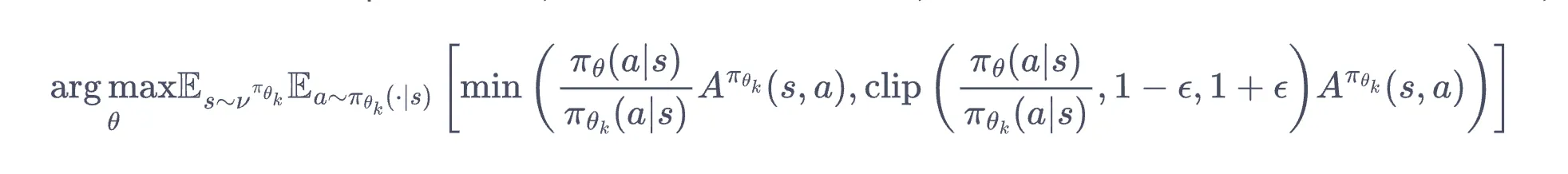12 PPO PPO 优化目标和 TRPO 相同,但求解没有那么多烦人步骤. 【两种方法约束新解】 PPO-惩罚:将 KL 散度放进 loss,但是系数计算有门道 PPO-截断(效果更好):求解 $theta$ 参数时,新旧策略概率比直接截断 代码实践 若动作连续,也可以输出均值和标准差.