7.6.resnet
回忆提纲
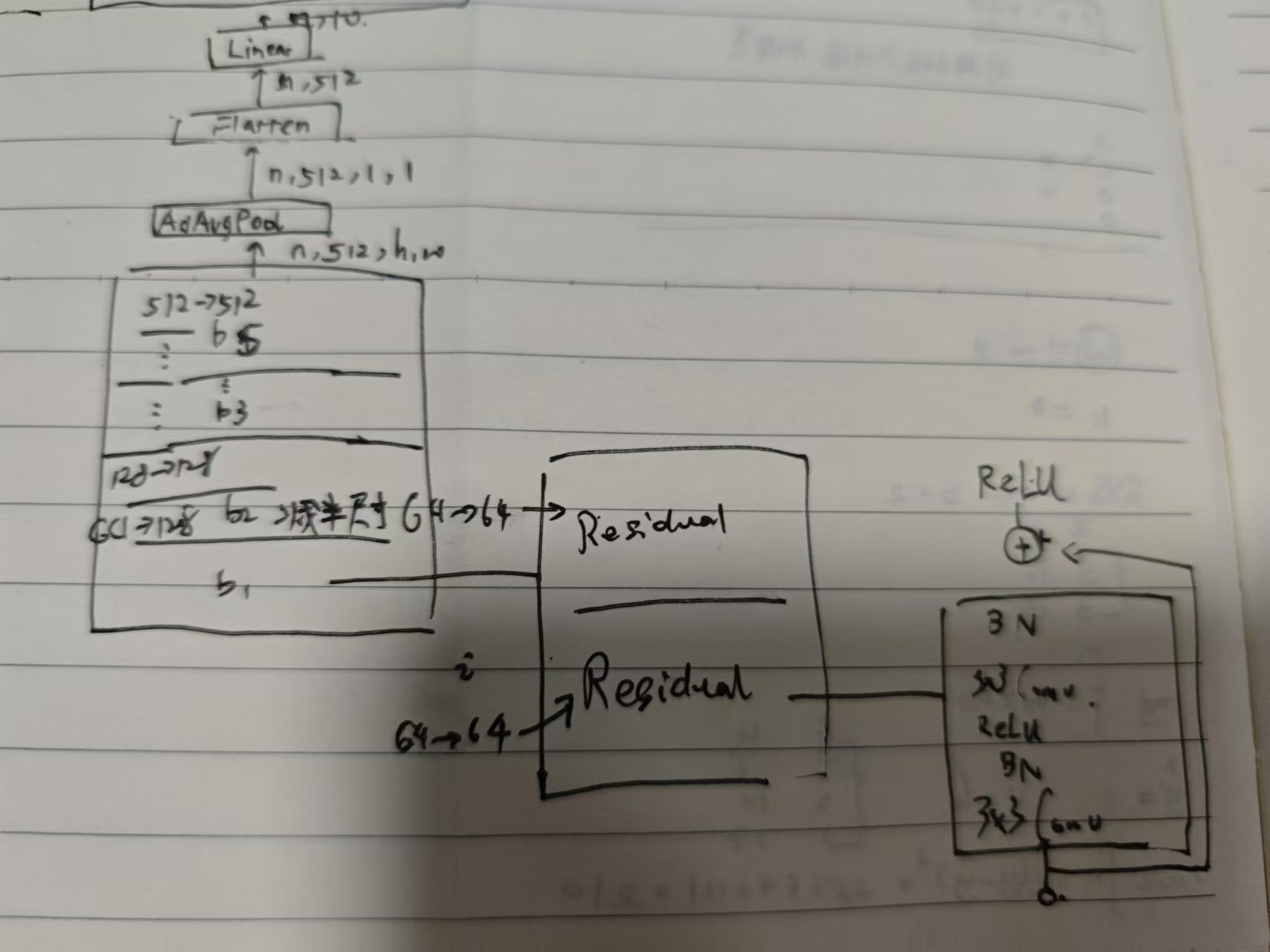
- resnet 块一条路径为 Conv + BN + ReLU + Conv + BN,保持形状不变,将输入直接加到输出,再跟一个 ReLU.
- 为什么有用? 当网络深度加深时,可能出现网络退化(不是梯度爆炸)。事实上,可能中间的某一层已经是最优网络。resnet 非常容易学习到恒等映射,避免了网络退化。ref: https://blog.csdn.net/fengdu78/article/details/128451148
手绘:
截图:
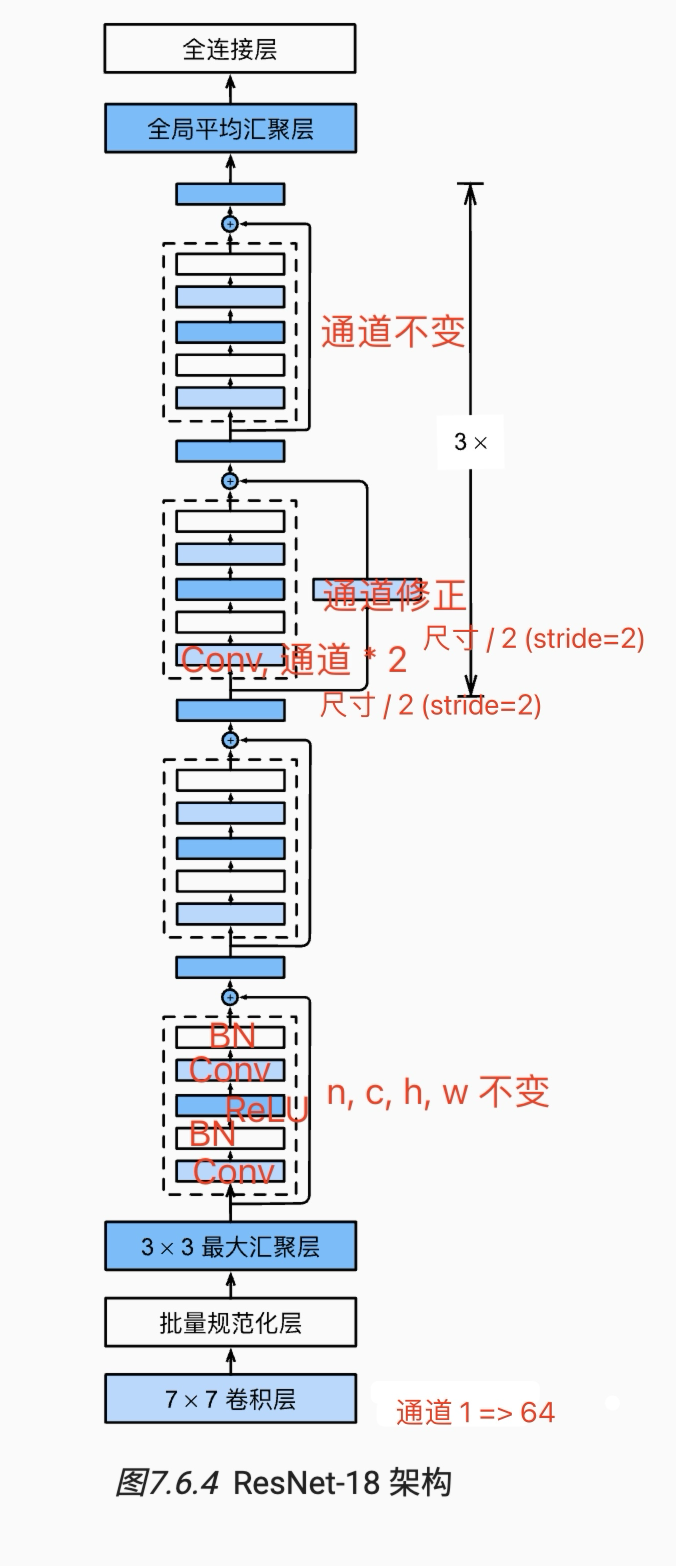
通道数不断增加(在每一 block 的第一个卷积层增加):
conv5 output shape: (1, 64, 112, 112)
batchnorm4 output shape: (1, 64, 112, 112)
relu0 output shape: (1, 64, 112, 112)
pool0 output shape: (1, 64, 56, 56)
sequential1 output shape: (1, 64, 56, 56)
sequential2 output shape: (1, 128, 28, 28)
sequential3 output shape: (1, 256, 14, 14)
sequential4 output shape: (1, 512, 7, 7)
pool1 output shape: (1, 512, 1, 1)
dense0 output shape: (1, 10)
loss 0.016, train acc 0.996, test acc 0.919
耗时 3m 0.1s,train acc 十分惊人
练习
- :numref:
fig_inception中的Inception块与残差块之间的主要区别是什么?在删除了Inception块中的一些路径之后,它们是如何相互关联的? - 参考ResNet论文 :cite:
He.Zhang.Ren.ea.2016中的表1,以实现不同的变体。 - 对于更深层次的网络,ResNet引入了“bottleneck”架构来降低模型复杂性。请试着去实现它。
- bottleneck 结构: 通过前后两个 Conv1x1,先降低通道,再恢复通道。ref: https://blog.csdn.net/DanTaWu/article/details/111468257
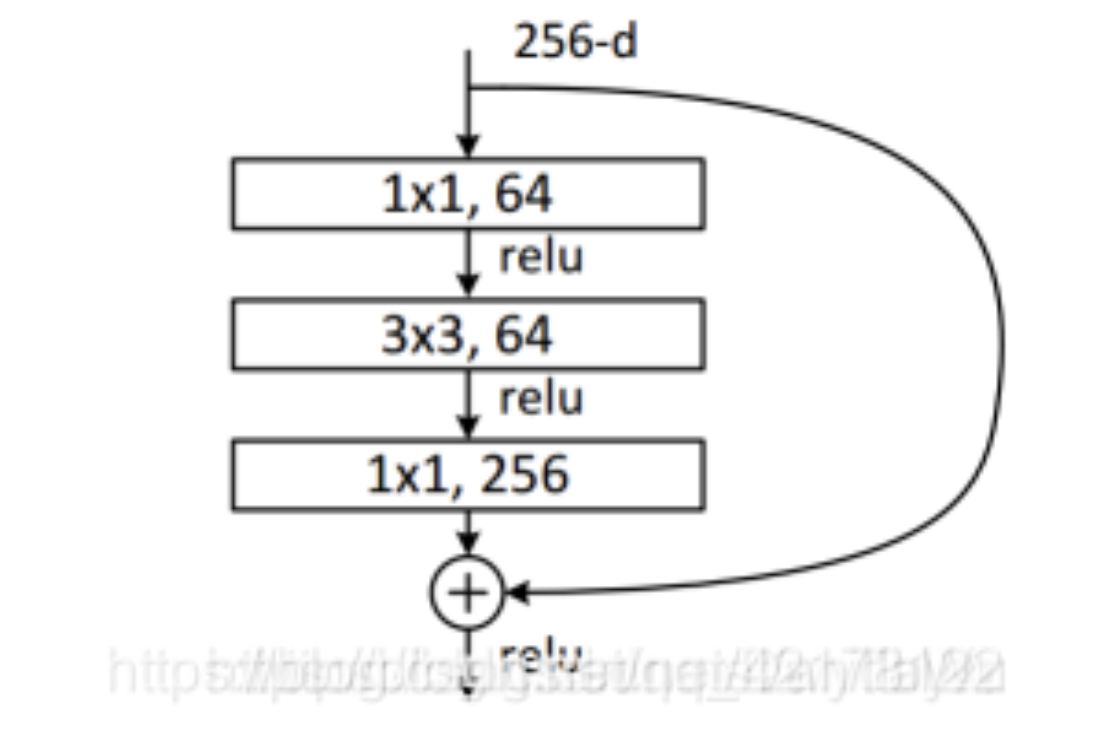
- bottleneck 结构: 通过前后两个 Conv1x1,先降低通道,再恢复通道。ref: https://blog.csdn.net/DanTaWu/article/details/111468257
- 在ResNet的后续版本中,作者将“卷积层、批量规范化层和激活层”架构更改为“批量规范化层、激活层和卷积层”架构。请尝试做这个改进。详见 :cite:
He.Zhang.Ren.ea.2016*1中的图1。- 改变后,需要使用 batch_size = 64, lr = 0.005,即缩小学习率和 batchsize
- 为什么即使函数类是嵌套的,我们仍然要限制增加函数的复杂性呢?
- 计算资源问题。
- 复杂度越高,优化算法找到良好局部最小值的可能性也会下降。
- 更简单的模型更容易解释。
- 更简单的模型泛化能力更好,因为它不依赖特定训练集的特征。