10.3.注意力评分函数
$$ f(x) = sum_(i = 1)^n "softmax"(-1 / 2 ((x - x_i)w)^2)y_i $$
该公式括号内部可称为”评分函数“
masked_softmax
def masked_softmax(X, valid_lens):
"""在最后一个轴上掩蔽元素后,执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
# 使用时,X.shape = (batch_size, num_queries, num_keys),表示注意力权重。此函数掩盖部分 keys 的注意力权重
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
# 对于第一个 batch,每个 num_keys 保留 2
# 对于第二个 batch,每个 num_keys 保留 3
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
>>>
tensor([[[0.5980, 0.4020, 0.0000, 0.0000],
[0.5548, 0.4452, 0.0000, 0.0000]],
[[0.3716, 0.3926, 0.2358, 0.0000],
[0.3455, 0.3337, 0.3208, 0.0000]]])
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
>>>
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
[0.4125, 0.3273, 0.2602, 0.0000]],
[[0.5254, 0.4746, 0.0000, 0.0000],
[0.3117, 0.2130, 0.1801, 0.2952]]])
加性注意力
-
学习不同维度的查询与键的注意力。下面输出为实数. q 的大小为 query_size,k 大小为 key_size
-
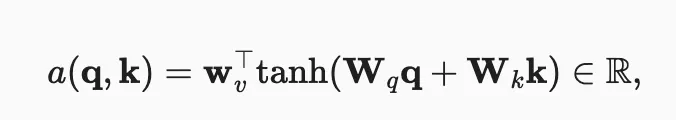
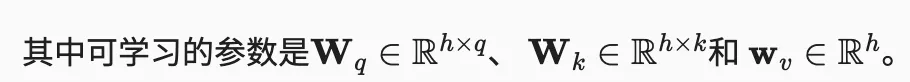
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
# 输入的 queries 的形状: (batch_size, num_queries, query_size)
# 输入的 queries 的形状: (batch_size, num_keys, key_size)
queries, keys = self.W_q(queries), self.W_k(keys)
# - 在维度扩展 unsqueeze 后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
# - unsqueeze(n) 在第 n 维添加一维,长度为 1
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# attension_weights.shape = (batch_size, num_queries, num_keys)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)
# return 的形状: (batch_size, num_queries, value_dim)
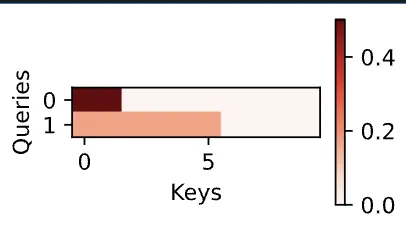
# - queries: 2 个批量,分别 1 个 query,分别长度为 20
# - 这个 query 查询对所有 key 的权重,都是一样的(虽然参数随机生成,但过程中用到的参数一样)
# - mask 仅保留前两个 key,所以其权重都是 1 / 2,结果 value 为前两个 key 所存 value 的均值
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(
2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.3)
attention.eval()
attention(queries, keys, values, valid_lens), values
>>>
(tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>),
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.],
[32., 33., 34., 35.],
[36., 37., 38., 39.]],
[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.],
[32., 33., 34., 35.],
[36., 37., 38., 39.]]]))
- 这两个 batch 对 10 个 key 的注意力分配:
缩放点积注意力
- 原文很简洁:

class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d: 即 query_size)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
- [done]